
Die offenen Grundlagen von Cloudera ermöglichen Unternehmen den Zugriff auf 100 % ihrer Daten, unabhängig vom Speicherort.
Branchenübergreifend überdenken Datenteams, wie sie Systeme aufbauen und betreiben können, die mehr als nur Informationen speichern: Sie wollen Daten in Intelligenz verwandeln. Ebenso wichtig ist die Interoperabilität dieser Systeme. KI-Modelle, Feature-Pipelines, Business-Intelligence-Berichte (BI) und Batch-Jobs erstrecken sich häufig über mehrere Teams und Engines. Der Austausch von Daten zwischen diesen Grenzen ohne Kopieren oder Refactoring ist heute eine grundlegende Anforderung.
Traditionell haben sich Unternehmen auf eine zweistufige Architektur verlassen: Data Warehouses, die für BI und Berichterstellung optimiert sind, und Data Lakes, die für umfangreiche Anwendungen im Bereich KI und maschinelles Lernen (ML) konzipiert sind. Diese Trennung hatte ihren Preis: komplexe Datenbewegungen, spezialisierte Engineering-Lösungen und doppelte Speicherung über Systeme hinweg, die selten synchronisiert waren.
Die offene Lakehouse-Architektur von Cloudera geht diese Herausforderung an und vereint analytische (BI, Ad-hoc-Abfragen) und KI-Workloads (prädiktive und generative KI oder GenAI) auf einer einzigen, kontrollierten Datenbasis. Mit offenen Tabellenformaten wie Apache Iceberg ermöglicht diese vereinheitlichte Datenarchitektur Unternehmen, Daten zu verarbeiten (nicht umgekehrt) und bietet die Grundlage für die Ausführung von KI-Workloads, die näher an den Daten sind. KI-Workloads auf dem Lakehouse können direkt auf verwalteten, versionierten und hochwertigen Daten arbeiten.
Cloudera ist das einzige Daten- und KI-Plattformunternehmen, das KI überall in Daten integriert. Aufbauend auf unserem bewährten Open-Source-Fundament bieten wir ein einheitliches Cloud-Erlebnis, das Public Clouds, Rechenzentren und die Edge zusammenführt.
Die Bedeutung offener Grundlagen für die Ausführung von KI-Workloads
Im letzten Jahrzehnt haben Unternehmen gelernt, dass Leistung und Skalierbarkeit allein nicht ausreichen und Flexibilität und Interoperabilität langfristigen Erfolg bestimmen. KI-Workloads hängen insbesondere von der Fähigkeit ab, unterschiedliche Datenquellen, Frameworks und Tools zu verwenden, ohne durch proprietäre Formate oder Systeme eingeschränkt zu sein.
Genau hier haben offene Tabellenformate wie Apache Iceberg die Architektur von Datenplattformen neu gestaltet. Iceberg trennt die logische Definition einer Tabelle von ihrem physischen Speicherlayout, sodass mehrere Engines und Frameworks dieselben Daten mit vollständigen Transaktionsgarantien lesen und schreiben können. Diese Offenheit ermöglicht die Weiterentwicklung der Infrastruktur und die Einführung neuer Rechenengines, ohne dass Pipelines neu geschrieben werden müssen.
Für den Betrieb von Produktionspipelines ist eine einheitliche Plattform erforderlich, die Daten, Modelle und Governance in jeder Phase des KI-Lebenszyklus miteinander verbinden kann. Im Kern gibt es Daten- und Feature-Engineering-Pipelines, die kontinuierlich rohe strukturierte, semistrukturierte und unstrukturierte Daten in KI-fähige Features umwandeln und dabei Lineage und Reproduzierbarkeit für das Modelltraining und die Evaluierung gewährleisten.
Über das traditionelle ML hinaus führt GenAI neue betriebliche Anforderungen ein. Teams benötigen Infrastruktur und Zugriff auf Daten für die Retrieval-Augmented Generation (RAG), die Feinabstimmung großer Sprachmodelle (LLMs) anhand privater Daten und den Aufbau agentischer Workflows, die Modelle, Prompts und Model Context Protocols (MCPs) (APIs) kombinieren, um bereichsspezifische Aufgaben zu lösen. Diese Workloads basieren sowohl auf tabellarischen als auch auf unstrukturierten Daten (Text, Dokumente, Bilder und Einbettungen), die alle unter einer einzigen Daten- und Metadatenebene verwaltet werden. Darüber hinaus ist eine skalierbare Inferenzebene unerlässlich für die sichere und effiziente Bereitstellung und Nutzung dieser Modelle.
Da KI-Workloads zunehmend multimodal und agentisch sind, wird der Zugriff auf Kataloge und Metadaten ebenso wichtig. KI-Pipelines, Abrufsysteme und autonome Agenten sind alle auf Metadaten angewiesen, um Datensätze zu finden, Trainingszustände zu reproduzieren und Lineages aufrechtzuerhalten. Ein offener Katalog bietet diesen Systemen eine universelle Möglichkeit zur Abfrage, Registrierung und Verfolgung von Datensätzen – unabhängig davon, wo oder wie diese verarbeitet werden.
Die offene Grundlage von Cloudera ermöglicht Unternehmen die Unterstützung des gesamten Spektrums an analytischen, vorausschauenden und GenAI-Workloads.
Die einheitliche Daten- und KI-Plattform von Cloudera
Das offene Data Lakehouse von Cloudera vereint Datenverarbeitung, Analytik und KI auf derselben kontrollierten Architektur, indem es auf offenen Grundlagen wie Apache Iceberg und REST-Katalog aufbaut. Die Plattform basiert auf dem Prinzip, dass Workloads (ob analytisch oder KI) dort ausgeführt werden sollten, wo sich die Daten bereits befinden. Durch die Beseitigung von Reibungsverlusten beim Verschieben oder Duplizieren von Daten können Teams kontinuierliche Pipelines aufbauen, die die Erfassung, Transformation, Analyse und Modelloperationen mit vollständiger Lineage-Nachverfolgung und Governance umfassen.
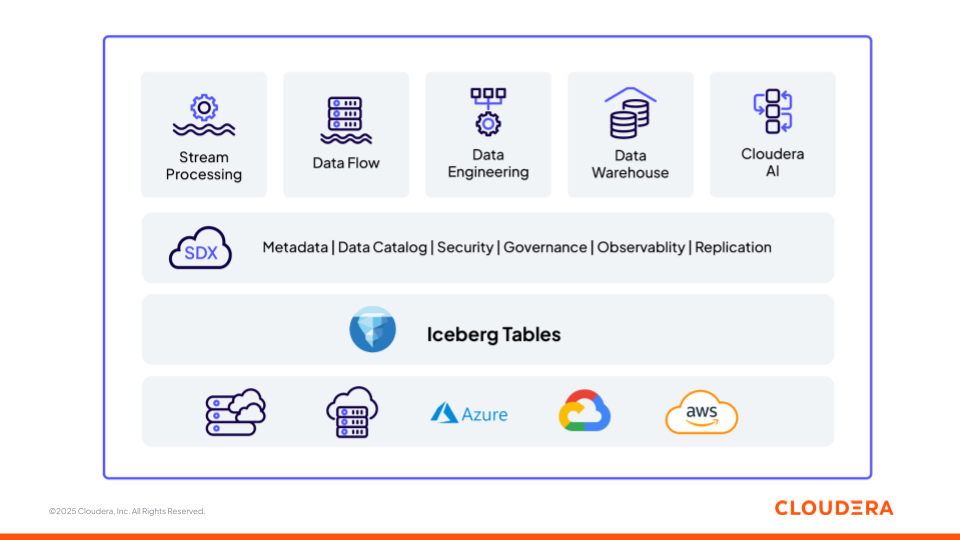
Abbildung 1: Die Daten- und KI-Plattform von Cloudera auf offener Grundlage (Apache Iceberg)
Wir werden nun untersuchen, wie die verschiedenen Komponenten der Plattform von Cloudera (Abbildung 1) Teams beim Aufbau von ML-Pipelines und GenAI-Anwendungen sowie in den verschiedenen Phasen des Daten- und KI-Lebenszyklus – von der Erfassung bis zur Inferenz – unterstützen, während sie als eine interoperable Plattform fungieren. Jede Komponente basiert auf offenen Standards, was Flexibilität und Interoperabilität in allen Umgebungen gewährleistet.
Speicher: Apache Iceberg
Apache Iceberg ist das offene, versionierte und transaktionale Tabellenformat, das der Lakehouse-Architektur von Cloudera zugrunde liegt. Iceberg ermöglicht Schema-Entwicklung, Zeitreisen und atomare Operationen, sodass sowohl analytische als auch KI-Workloads konsistent mit denselben regulierten Daten arbeiten können. Cloudera bietet eine verwaltete und versionsbasierte Grundlage, die sicherstellt, dass jedes Modell, jeder Prompt oder jede Abrufaufgabe auf einer einheitlichen und nachverfolgbaren Datenansicht basiert.
Die nativen Funktionen von Iceberg wie die Schemaentwicklung entsprechen ebenfalls weitgehend der Entwicklung von KI-Datensätzen. Feature-Stores, Trainingsdatensätze und Abrufkorpora können alle dieselben Iceberg-Tabellen im Lakehouse von Cloudera gemeinsam nutzen, wobei Snapshots verwendet werden, um konsistente Ansichten für das Training einzufrieren, während weiterhin neue Daten für die Inferenz eingehen. Dadurch wird die Trennung zwischen analytischen Tabellen und KI-spezifischem Speicher aufgehoben.
Aufnahme: Cloudera Bewegtdaten
Cloudera DataFlow, basierend auf Apache NiFi, bildet die Grundlage für die kontinuierliche Datenübertragung in das Lakehouse. Es ermöglicht die Aufnahme mit geringer Latenz aus verschiedenen Unternehmensquellen – Datenbanken, APIs, IoT-Geräten und Ereignisprotokollen – zur Unterstützung von sowohl Batch- als auch Streaming-Workloads. Dank der jüngsten Innovationen bei der nativen Integration von Apache Iceberg in NiFi können Daten nun ohne Zwischenlagerung direkt in das offene Lakehouse geschrieben werden. Durch diese enge Verknüpfung zwischen NiFi und Iceberg wird die Komplexität der Datenpipeline reduziert und die Datenerfassung näher an das offene Tabellenformat selbst herangeführt.
In Anwendungsfällen in Echtzeit bilden NiFi, Apache Kafka und Apache Flink eine ereignisgesteuerte Erfassungsstruktur: NiFi koordiniert und leitet Daten weiter, Kafka sorgt für dauerhaften Datenstrom und Flink ermöglicht die Anreicherung in Echtzeit, bevor die Daten in Iceberg gespeichert werden. Dieses Design gewährleistet, dass die Daten bei allen nachgelagerten Benutzern sowohl aktuell als auch regelkonform bleiben. Dieser kontinuierliche Fluss multimodaler Daten ist auch die Grundlage für KI-Workloads im Lakehouse. Durch die kontinuierliche Bereitstellung von Daten in Echtzeit in Iceberg-Tabellen unter einheitlicher Governance können Unternehmen GenAI-Systeme mit zeitnahen, bereichsspezifischen Informationen versorgen, wodurch RAG-Pipelines und agentische Workflows präziser, fundierter und zuverlässiger werden.
Katalog: Cloudera Iceberg REST-Katalog
Der Cloudera Iceberg REST-Katalog (basierend auf der offenen REST-Spezifikation) bietet einen zentralisierten und interoperablen Metadatendienst, der jeder Drittanbieter-Engine (wie Snowflake, Redshift und Databricks), die die offene Spezifikation unterstützt, den Zugriff auf Iceberg-Tabellen ohne Kopieren ermöglicht. Dieser Aspekt ist für Unternehmen von entscheidender Bedeutung, da sie nicht auf eine einzige Rechenengine einer einzigen Plattform beschränkt sind und somit flexibel die für die jeweilige Aufgabe am besten geeignete Rechenleistung auswählen können. Benutzer können ihre bevorzugten Tools verwenden, während die gleichen Sicherheits- und Governance-Richtlinien von Cloudera überall für die Daten gelten und so die Konsistenz in allen Umgebungen gewährleisten.
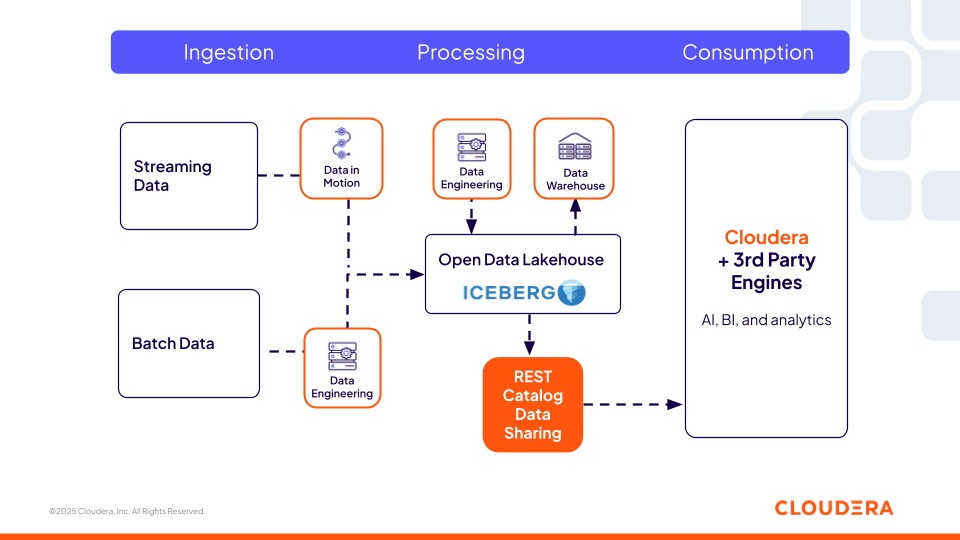
Abbildung 2: Der Iceberg REST-Katalog von Cloudera ermöglicht die Interoperabilität mit Engines von Drittanbietern
Diese Katalogebene ist für Feature-Engineering-Pipelines, agentische Workflows und Abrufsysteme von entscheidender Bedeutung, um regulierte Datensätze dynamisch zu lokalisieren und darauf zuzugreifen. KI-Agenten können Iceberg-Tabellen mithilfe des REST-Katalogs abfragen, genau wie einen Wissensgraphen mit Unternehmensdaten. Sie können verfügbare Tabellen ermitteln, ihre Schemata interpretieren und Metadaten von Tabellen wie Partitionierung, Snapshots und Abstammung analysieren, um die zu verwendenden Datensätze zu bestimmen.
Sicherheit und Governance: Cloudera SDX
Cloudera Shared Data Experience (SDX) ist das einheitliche Sicherheits- und Governance-Framework, das jeden Dienst von der Aufnahme bis zur Inferenz abdeckt. SDX bietet eine einzige, einheitliche Ebene für Daten-Lineage, Auditing, Zugriffskontrolle und Durchsetzung von Richtlinien und stellt so sicher, dass jede Workload unabhängig vom Ausführungsort dasselbe Sicherheitsmodell übernimmt. Es lässt sich in Unternehmensidentitätssysteme (LDAP, SSO, OAuth) integrieren und unterstützt detaillierte, rollen- und attributbasierte Zugriffskontrollen für strukturierte und unstrukturierte Daten.
Durch die Verknüpfung von SDX mit der Open Lakehouse Foundation stellt Cloudera sicher, dass Daten, Modelle und KI-Agenten innerhalb derselben festgelegten Grenzen arbeiten – und bietet so Transparenz, Reproduzierbarkeit und Vertrauen sowohl für analytische als auch für GenAI-Workloads.
Cloudera Daten- und KI-Services
Die einheitliche Services-Ebene vereint alle funktionalen Fähigkeiten, die Teams benötigen, um KI zu transformieren, zu analysieren und zu operationalisieren, während sie gleichzeitig mit denselben regulierten Daten arbeiten.
Data Engineering
Cloudera Data Engineering, aufgebaut auf den Open-Source-Plattformen Apache Spark und Apache Airflow, bietet einen serverlosen Dienst zum Aufbau, Orchestrieren und Skalieren von Datenpipelines direkt auf Iceberg-Tabellen – sodass zuverlässige, reproduzierbare ETL- und Feature-Pipelines für Analyse- und KI-Workloads in hybriden Umgebungen möglich sind.
KI-Dienste
Die Cloudera AI-Services-Ebene operationalisiert den gesamten Lebenszyklus der KI, angefangen vom Modelltraining und der Feinabstimmung bis hin zur sicheren Bereitstellung – alles läuft nativ auf derselben verwaltetenDatengrundlage mit Iceberg. Sie vereint Modellentwicklung, Registrierung und Inferenz in einem einzigen Workflow, der Datenverarbeitung und KI-Operationen miteinander verbindet.
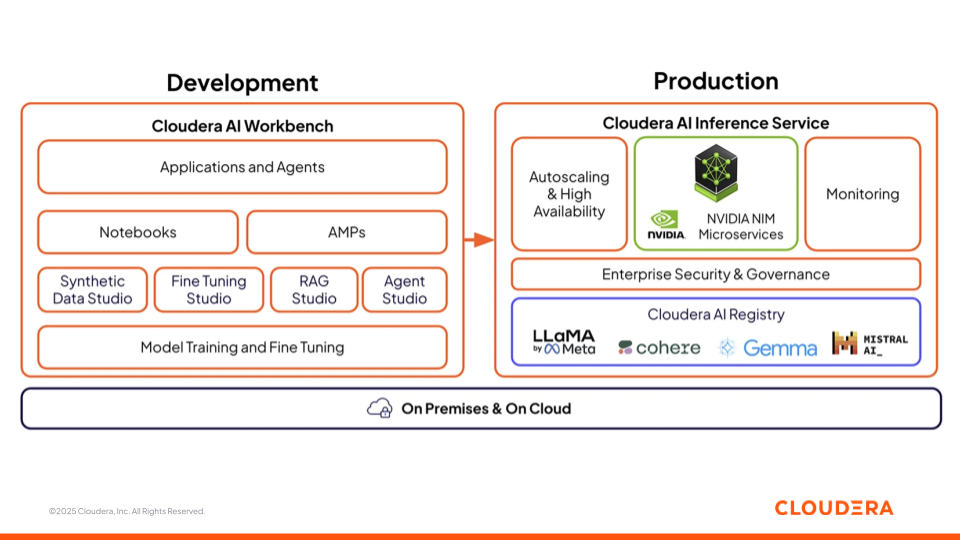
Abbildung 3: Das Angebot von Cloudera AI mit AI Workbench und Inference Service
Cloudera AI Workbench
Cloudera AI Workbench ist die kollaborative Umgebung, in der Data Scientists, Analysts und Engineers Modelle entwickeln, optimieren und testen. Sie vereint Notebooks, Low-Code-Anwendungsentwickler (AMPs) und spezialisierte Studios für jede Phase der KI-Entwicklung. Zur Beschleunigung der KI-Entwicklung und -Einführung unterstützt Cloudera AI Workbench vier KI-Studios, die die Lücke zwischen Geschäfts- und Technikteams schließen und die Zusammenarbeit bei KI-Projekten fördern.
- Synthetic Data Studio generiert synthetische Datensätze für Tests und Modelltraining, wenn reale Daten begrenzt oder eingeschränkt sind.
- Fine-Tuning Studio passt offene Foundation Models mit unternehmensspezifischen Datensätzen für höhere Relevanz und Genauigkeit an.
- RAG Studio erstellt RAG-Pipelines, die LLMs (wie OpenAI, Anthropic, Amazon Bedrock) mit relevanten privaten Daten verbinden, um fundierte, kontextbezogene Ergebnisse zu erzielen.
- Agent Studio ermöglicht die Erstellung mehrstufiger, agentischer Workflows, die Modelle, MCPs, APIs und interne Datenquellen zur Automatisierung bereichsspezifischer Aufgaben nutzen.
All diese Funktionen werden auf dem offenen Lakehouse (auf der Grundlage von Iceberg) ausgeführt und bieten Teams einen kontrollierten Zero-Copy-Zugriff auf die für bestimmte Aufgaben erforderlichen Daten.
Cloudera MCP Server
Cloudera erweitert außerdem die Offenheit seiner KI-Plattform durch eine Reihe neuer MCP-Dienste, beginnend mit dem Open-Source-Dienst Cloudera AI Workbench MCP Server. Dieser Dienst ist für die Integration von KI-Systemen konzipiert und ermöglicht agentische Funktionen und Tool-Aufrufe innerhalb der AI Workbench. Er bietet den Rahmen für LLMs, um sicher mit den Funktionen und Komponenten von Cloudera AI Workbench zu interagieren und Modelle, Daten und Anwendungen in automatisierte Unternehmens-Workflows zu integrieren. In dieser Architektur können intelligente Agenten argumentieren, handeln und Aufgaben in der vertrauenswürdigen, kontrollierten Cloudera-Umgebung automatisieren, während sie gleichzeitig die Sicherheit, Kontrolle und Prüfbarkeit aufrechterhalten, die in regulierten Branchen erforderlich sind.
Cloudera AI Inference Service
Der Cloudera AI Inference Service bringt Modelle mit automatischer Skalierung, Hochverfügbarkeit und End-to-End-Observabilität in Produktion. Er unterstützt sowohl traditionelle ML-Modelle als auch große Sprachmodelle (LLMs) und liefert Vorhersagen und Antworten mit geringer Latenz. Modelle können als REST- oder gRPC-Endpunkte mit Sicherheit auf Unternehmensniveau bereitgestellt werden, wodurch ein zuverlässiger und einheitlicher Zugriff von Anwendungen und Agenten gewährleistet wird.
Die in die Inferenzebene integrierte Cloudera AI Registry bietet ein zentralisiertes Modelllebenszyklusmanagement mit MLflow-kompatiblen APIs für Nachverfolgung, Versionierung, Artefakt-Speicherung und Lineage. Sie haben die Wahl zwischen verschiedenen offenen und unternehmensweiten Sprachmodellen wie LlaMa, Cohere, Gemma und Mistral.
Die Inferenzschicht beinhaltet zudem integrierte Überwachung und Beobachtbarkeit, sodass Teams Latenz, Durchsatz und Modellabweichungen verfolgen können, während vollständige Lineage und Compliance durch SDX Governance erhalten bleiben. Dadurch wird sichergestellt, dass die Modellvorhersagen erklärbar und nachvollziehbar sind, was eine zentrale Voraussetzung für KI auf Unternehmensebene ist.
Die Zukunft steht im Zeichen der KI – und die KI wird von allen Daten gespeist.
Der Erfolg von KI hängt ebenso sehr von der Datenarchitektur wie von der Leistungsfähigkeit des Modells/Agenten ab. Das Lakehouse bildet diese Grundlage und vereint Analyse-, Betriebs- und KI-Workloads auf einer einzigen, kontrollierten Datenebene. Die Verwendung offener Standards stellt sicher, dass Daten, Metadaten und Modelle ohne Reibungsverluste mit anderen Tools, Clouds und Teams zusammenarbeiten können.
Zusammen vervollständigen Cloudera AI Workbench, AI Inference Service und die integrierte AI Registry den Daten-zu-KI-Lebenszyklus auf einer offenen Lakehouse-Grundlage. Direkt auf verwalteten Iceberg-Tabellen und offenem Metadatenzugriff aufgebaut, stellt dieser Stack sicher, dass jedes Modell, jeder Prompt und jeder Agent auf vertrauenswürdigen, versionierten Daten arbeitet.
Die Zukunft der Unternehmens-KI wird nicht durch proprietäre Stacks bestimmt werden, sondern durch offene Grundlagen, die Daten, Governance und Intelligenz durch gemeinsame Standards und transparente Interoperabilität vereinen.
Um mehr darüber zu erfahren, wie Sie mit Cloudera Daten sicher in großem Maßstab vorbereiten, integrieren und analysieren können, sehen Sie sich unsere Produktdemos an oder melden Sie sich für eine kostenlose 5-Tage-Testversion an.
