Demokratisierung von Daten für KI durch Interoperabilität zwischen Engines und Zero-Copy-Datenzusammenarbeit




So ermöglicht Cloudera Iceberg REST-Katalog offene, KI-fähige Unternehmen
Interoperabilität ist seit langem ein Modewort und keine Fähigkeit, auf die sich Unternehmen in der Praxis verlassen können. Stattdessen müssen Data Architects oft fragmentierte Systeme miteinander verbinden, Chief Data Officers sind aufgrund einer isolierten Governance mit enormen Risiken und einer Abhängigkeit von bestimmten Anbietern konfrontiert, und Plattformverantwortliche können ihren Teams keine einheitliche Datenansicht bieten. Ob durch Fusionen, Multi-Cloud-Strategien oder externe Partnerschaften bedingt, das Muster wiederholt sich: steigende Kosten, langsamere Innovation und begrenzte Fähigkeit, KI mit Zuversicht zu skalieren.
Bei Cloudera haben wir unseren Kunden dabei geholfen, diese Herausforderungen zu meistern – unzusammenhängende Metadatenebenen, doppelte Datenpipelines und Governance-Modelle, die sich nicht auf alle Tools erstrecken – und dabei stets danach gestrebt, offene, KI-fähige Unternehmen zu ermöglichen, die Interoperabilität im großen Maßstab erschließen.
Warum Offenheit für Unternehmens-KI wichtig ist
Für die Skalierung von KI-Workloads benötigen Unternehmen Transparenz und Kontrolle über die Daten, die diese Workloads speisen. Metadaten-Intelligenz spielt dabei eine entscheidende Rolle, da sie Unternehmen ermöglicht, zu verstehen, wo Daten gespeichert sind, wie sie strukturiert sind und wie sie in verschiedenen Teams und Tools verwendet werden.
Mit offenen Standards wie Apache Iceberg und dem Iceberg REST-Katalog erhalten Unternehmen eine einheitliche Metadatenebene, die den Austausch von Daten ohne ETL unterstützt, Governance durchsetzt und eine sichere Interoperabilität zwischen Analyse- und KI-Systemen ermöglicht. Diese Grundlage verwandelt fragmentierte Infrastrukturen in eine vernetzte, KI-fähige Datenarchitektur, in der Metadaten der Schlüssel zu einem schnelleren Zugriff auf Erkenntnisse bei gleichbleibender Vertrauenswürdigkeit sind.
Offen, sicher und einfach: Cloudera Iceberg REST-Katalog
Der Cloudera Iceberg REST-Katalog unterstützt unser offenes Data Lakehouse und unterstützt Unternehmen bei der Vereinfachung ihrer Architektur, der Reduzierung von doppelter Arbeit und der Erweiterung des sicheren Datenzugriffs, wo immer dies erforderlich ist.
Er fungiert als universelle, interoperable Metadatenebene und bietet Zero-Copy-Zugriff auf Iceberg-Tabellen über Tools, Clouds und Teams hinweg, sodass Open-Source- und Drittanbieter-Tools auf dieselben Daten zugreifen können. Zu den Merkmalen und Vorteilen gehören:
- Offen und engine-unabhängig: Bietet standardbasierte APIs, die Tools wie Athena, Databricks, Redshift und Snowflake unterstützen und Interoperabilität ohne Anbieterabhängigkeit ermöglichen.
- Entkoppelt durch Design: Entkoppelt Abfrage-Engines von Backend-Metastores, reduziert die Komplexität und erhöht die Portabilität zwischen verschiedenen Umgebungen.
- Zugriff auf Metadaten in Echtzeit: Unterstützt schnelle, aktuelle Metadatenabfragen aus Iceberg-kompatiblen Metastores und verbessert die Datentransparenz in den Teams
- Verwaltet und sicher: Erweitert detaillierte Zugriffskontrollen, Berechtigungen auf Zeilenebene und die Integration von Identity Access Management (IAM) für Unternehmen (z. B. LDAP und OAuth2) auf alle verbundenen Systeme und gewährleistet so eine einheitliche Durchsetzung von Richtlinien im großen Maßstab.
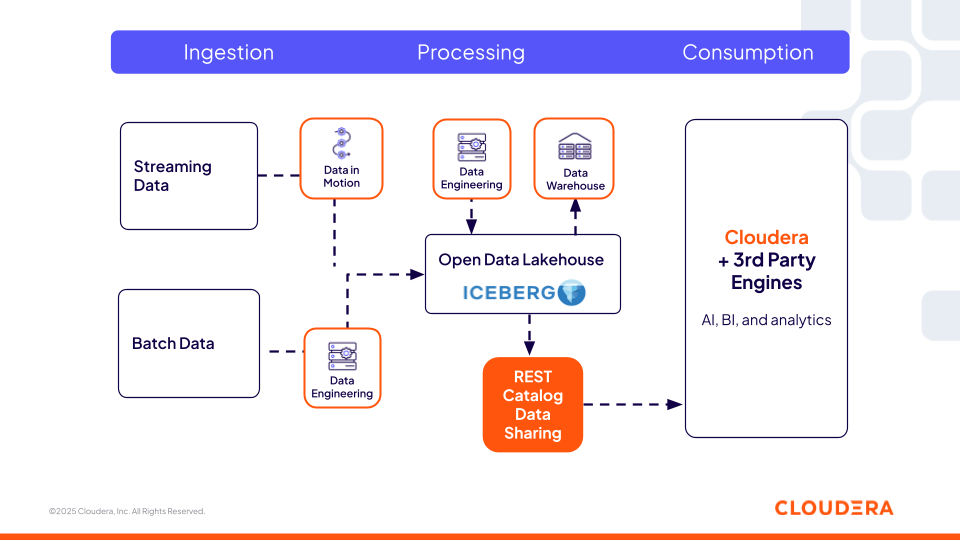
Abbildung 1. Der Iceberg REST Catalog von Cloudera bietet eine universelle, interoperable Metadatenebene, über die Open-Source- und Drittanbieter-Tools auf dieselben Daten zugreifen können.
Praxisnahe Anwendungsfälle und Auswirkungen des Iceberg REST-Katalogs
Die folgenden Beispiele aus der Praxis veranschaulichen, wie Unternehmen den Iceberg REST-Katalog zur Vereinfachung ihres Datenstacks, Senkung der Gesamtbetriebskosten (TCO) und Beschleunigung der Zeit bis zur Wertschöpfung nutzen – und dabei die Daten dort belassen, wo sie hingehören.
Zusammen zeigen diese Beispiele, wie der offene und interoperable Ansatz von Cloudera KI-Ergebnisse beschleunigt, die betriebliche Effizienz auf Unternehmensebene steigert und Sicherheit und Compliance ermöglicht.
Datenfreigabe: Skalieren Sie KI-Anwendungen auf über 3.000 plattformübergreifende Nutzer
Ein Hersteller von Luxusautos stand vor immer größeren Herausforderungen beim sicheren Datenaustausch mit einem externen Partner über Databricks. Herkömmliche Methoden basierten auf Datenduplikation, was mit Kosten, Komplexität und mangelnder architektonischer Flexibilität verbunden war.
Durch die Einführung des Iceberg REST-Katalogs konnte der Kunde einen sicheren, ETL-freien Datenaustausch zwischen internen Systemen und externen Plattformen realisieren. Dieser offene, standardbasierte Ansatz ermöglichte ihnen die Auswahl der besten Tools für die jeweilige Aufgabe – Spark für komplexe Datenpipelines und Impala für schnelle SQL-Analysen. Auf dieser Grundlage konnte das Unternehmen KI-Anwendungen auf mehr als 3.000 Benutzer skalieren und gleichzeitig die volle Governance und Kontrolle über den Datenzugriff behalten.
Data-Warehouse-Optimierung: Reduzierung der Datenbewegungskosten um 74 %
Nach einer Fusion stieß ein globales Satellitenunternehmen auf erhebliche Hindernisse bei der Vereinheitlichung fragmentierter Daten, die in proprietären Systemen gespeichert waren. Ohne eine einheitliche, interoperable Datenebene konnten ihre KI- und Analyseinitiativen nur langsam skaliert werden und waren schwer zu verwalten.
Die offene Data-Lakehouse-Architektur von Cloudera, die auf dem Iceberg REST-Katalog basiert, half dem Kunden bei der Konsolidierung dieser Silos und der Einrichtung einer einzigen zuverlässigen Quelle für alle seine KI- und Analyse-Workloads. Durch die direkte Abfrage verwalteter Iceberg-Tabellen in S3 entfiel der Bedarf an redundanten Datenpipelines und Replatforming-Maßnahmen, was zu einer Reduzierung der Datenbewegungskosten um 74 % führte.
Demo: Ein genauerer Blick auf den Datenaustausch über den Iceberg-REST-Katalog von Cloudera
Diese interaktive Demo erweckt den Iceberg REST-Katalog anhand eines Finanzdienstleistungsszenarios zum Leben. Bei der fiktiven Parent Bank nutzen verschiedene Teams ihre bevorzugten Tools wie Snowflake und AWS Athena, um sicher auf eine einzige kontrollierte Datenquelle zuzugreifen – ganz ohne komplexe ETL-Prozesse oder kostspielige Datenmigrationen.
Weitere Informationen zu diesem Angebot und den Vorteilen für Ihr Unternehmen finden Sie in den folgenden Ressourcen:
- Besuchen Sie unsere Produktseite, um mehr über das offene Data Lakehouse von Cloudera zu erfahren.
- Lesen Sie die Pressemitteilung, um die vollständige Ankündigung zur Vision von Cloudera für den offenen Datenaustausch zu erhalten.