Ein 5-Stufen-Framework zur Optimierung Ihrer Datenstrategie nach einer Unternehmensfusion


Anorganische Wachstumsstrategien wie Fusionen und Übernahmen (M&A) dienen als strategische Impulsgeber für Wachstum und ermöglichen Unternehmen die Realisierung von Umsatz- und Kostensynergien oder den schnellen Erwerb neuer Kompetenzen, die langfristige Wettbewerbsvorteile bieten. Heute beobachten wir beispielsweise, dass große Unternehmen kleinere, innovative KI-Start-ups übernehmen, um ihre KI-Transformation voranzutreiben und sich einen Wettbewerbsvorteil zu sichern.
Die Integration von Technologien spielt eine entscheidende Rolle bei der Wertsteigerung durch Fusionen und Übernahmen. Eine Studie von Deloitte kommt zu dem Schluss, dass die IT ein wesentlicher Treiber für Integrationsvorteile ist und mehr als 50 % aller Synergien ausmacht. Aufgrund der Vielzahl von Datensilos sowie unterschiedlicher Technologiearchitekturen und -umgebungen stehen Unternehmen jedoch vor mehreren Datenherausforderungen nach der Fusion, um Vorteile der Technologieintegration zu realisieren.
Dieser Artikel stellt einen Fünf-Stufen-Framework zur Bewältigung dieser Herausforderungen und Beschleunigung der Wertschöpfung bei Fusionen und Übernahmen vor. Dieses Framework stellt sicher, dass Ihre Datenstrategie nach der Fusion mit Cloudera die erforderlichen Funktionen zur Optimierung des Technologieintegrationsprozesses bereitstellt.
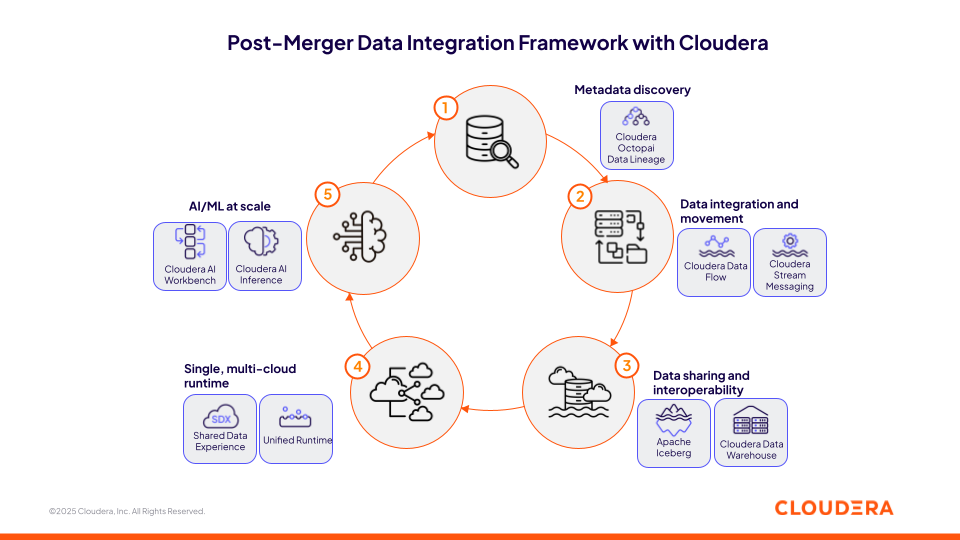
Abbildung 1: Datenintegrationsframework nach der Fusion mit Cloudera
1. Beschleunigung der Integration nach der Fusion mit Cloudera Octopai Data Lineage
Zu Beginn der Post-Merger-Integration wird die Datenermittlungsphase häufig zum Engpass, da fragmentierte und undokumentierte Quellen wichtige Analyse- und Compliance-Bemühungen verzögern. Cloudera Octopai Data Lineage begegnet dieser Herausforderung mit einer automatisierten, KI-gestützten Metadatenverwaltungs-Lösung, die die Datenermittlung, End-to-Ennd-Lineage und die Katalogisierung in komplexen Hybrid- und Multi-Cloud-Umgebungen beschleunigt.
Cloudera Octopai Data Lineage bildet Datenflüsse effektiv ab und füllt Metadatenlücken, wodurch eine mehrdimensionale Lineage entsteht, die Ursprünge und Transformationen für vollständige Transparenz nachverfolgt. Mit mehr als 60 nativen Integrationen und universellen Konnektoren für nicht-native Systeme optimiert Cloudera Octopai Data Lineage die Einbindung erworbener Datenbestände und verbessert so die Transparentheit, Qualität und Vertrauenswürdigkeit der Daten.
Beispielsweise ermöglicht diese Funktion bei Bankenfusionen die schnelle Identifizierung und Kennzeichnung risikobezogener Datensätze, wodurch die Einhaltung regulatorischer Standards wie BCBS 239 gewährleistet und gleichzeitig der Bedarf an umfangreichen manuellen Prüfungen oder Eingriffen minimiert wird.
2. Integration unterschiedlicher Datenquellen mit Cloudera Bewegtdaten
Die Integration unterschiedlicher Datenquellen und die Abschaffung komplexer, kundenspezifischer ETL-Pipelines stellen eine entscheidende Herausforderung nach der Fusion dar. Cloudera bietet leistungsstarke Funktionen für die Erfassung, Verarbeitung und Verteilung von Daten in Echtzeit und im Batch-Modus über Cloudera Data Flow (basierend auf Apache NiFi) und Cloudera Streaming (basierend auf Apache Kafka und Apache Flink).
Mit mehr als 450 Konnektoren bietet Cloudera Data Flow eine visuelle Drag-and-Drop-Oberfläche, um Daten aus einer Vielzahl von heterogenen Datenquellen aufzunehmen, ob lokal, in den Clouds oder an der Edge. Darüber hinaus bietet Cloudera Streaming eine Messaging-Bus-Architektur, die Quellsysteme von konsumierenden Systemen zwischen den beiden Entitäten entkoppelt und dadurch Punkt-zu-Punkt-Integrationen eliminiert, die die architektonische Komplexität erhöhen und höhere Kosten verursachen.
Während der Integration nach der Fusion können diese Funktionen den Datenaustausch zwischen Unternehmen erheblich beschleunigen und vereinfachen. Beispielsweise kann Cloudera Data Flow verwendet werden, um On-Premises-Daten aus alten Quellsystemen des übernommenen Unternehmens schnell in das Cloud-native Data Warehouse der Muttergesellschaft zu integrieren und so die Entscheidungsfindung zu beschleunigen.
3. Aufbau einer sicheren Ebene für den Datenaustand auf Cloudera Open Data Lakehouse mit Apache Iceberg
Der Datenaustausch zwischen fusionierenden Unternehmen ist eine wesentliche Voraussetzung für eine integrierte Entscheidungsfindung und die Gewinnung von Erkenntnissen. Dieser Prozess kann aufgrund der vielfältigen Technologien für explorative Datenanalyse und Business Intelligence sowie der unterschiedlichen Datensicherheitsmodelle, die von verschiedenen Systemen verwendet werden, komplex sein.
Ein Ansatz für ein offenes Data-Lakehouse, der Apache Iceberg, den Cloudera Iceberg REST Catalog und Cloudera Shared Data Experience (SDX) kombiniert, ermöglicht ermöglicht Unternehmen die Entwicklung einer einheitlichen Ebene für den Datenaustausch. Diese Ebene ist mit verschiedenen Analyse-Engines kompatibel (z. B. Snowflake, Databricks, AWS EMR, AWS Athena und Salesforce Data Cloud, sofern diese Engines Iceberg REST-Katalog unterstützen) und bietet ein detailliertes Sicherheits- und Governance-Modell zur Verwaltung des Zugriffs für eine Vielzahl von Benutzern, einschließlich der neu integrierten Data-Science-Teams.
Beispielsweise können zwei im Bereich der Arzneimittelherstellung tätige Gesundheitsunternehmen Cloudera nutzen, um ein GxP-konformes Data Lakehouse aufzubauen, das die Datenbestände der fusionierenden Unternehmen konsolidiert und gleichzeitig die Einhaltung gesetzlicher Vorschriften gewährleistet.
4. Standardisierung umweltübergreifender Initiativen in einer einzigen Multi-Cloud-Umgebung
Die unterschiedlichen Umgebungen, die für Analyseaktivitäten in den beiden fusionierenden Unternehmen verwendet werden, führen zu doppelten Vorgängen während des gesamten Datenlebenszyklus, einschließlich mehrerer Datenverarbeitungs-Pipelines für allgemeine Aufgaben wie Datenerfassung und -standardisierung.
Cloudera ermöglicht Unternehmen die Standardisierung von Daten- und KI-Prozessen auf einer gemeinsamen Laufzeitumgebung über verschiedene Private- und Public-Cloud-Umgebungen hinweg. Diese Fähigkeit basiert auf dem zugrunde liegenden containerisierten Infrastrukturmodell, das in allen Umgebungen verwendet wird, einem einheitlichen Mechanismus zur Benutzerauthentifizierung und -autorisierung (Cloudera SDX) und Cloudera Manager, der als zentrale Schnittstelle für die Verwaltung von Clustern in verschiedenen Bereitstellungsumgebungen und Regionen dient.
Im Kontext einer Fusion ist diese Standardisierung transformativ: Die beiden Unternehmen können ihre Datenlebenszyklusprozesse in einer einzigen Laufzeitumgebung integrieren, wodurch redundante Tools entfallen und der Austausch von Daten, Erkenntnissen und KI-Modellen erleichtert wird. Dies führt zu geringeren Technologie- und Arbeitskosten für den Datenbetrieb und die Entwicklung von KI-/ML-Modellen, einer höheren Produktivität der Anwender, einer Konsolidierung mehrerer Tools und einer Reduzierung von Datensilos.
5. Skalierung von KI-Initiativen überall mit Cloudera AI
Nach einer Übernahme oder Fusion besteht die unmittelbare Herausforderung darin, die unterschiedlichen Tools, Modelle und Data Scientists des neu erworbenen innovativen Start-ups zu integrieren und gleichzeitig die sich ändernden Kapazitätsanforderungen zu bewältigen. Mit Cloudera AI Workbench und AI Inference können Unternehmen KI-Initiativen durch Folgendes lokal oder in der Cloud skalieren:
Bereitstellung einer Container-basierten End-to-End-Lösung für Feature-Engineering, Modelltraining, Experimentverfolgung und Modellbereitstellung
Erleichterung des Austauschs von KI-Modellen, damit Data Scientists teamübergreifend zusammenarbeiten können
Nutzung von Hardware- und Software-Beschleunigungsdiensten von Clouder-Partnern, die den gesamten Data-Science-Lebenszyklus beschleunigen können, indem sie die Datenverarbeitungsleistung um das 20-Fache und die KI-Inferenzleistung um das bis zu 6-Fache verbessern
Mit Cloudera kann das integrierte Unternehmen erhebliche Kosteneinsparungen erzielen, indem es persistente, rechenintensive Workloads wie AI/ML-Modelldienste in On-Premises-Umgebungen verlagert. Noch wichtiger ist, dass die Markteinführungszeit für neue, kombinierte KI-Anwendungen verkürzt werden kann. Auf diese Weise kann das Unternehmen schnell den „Wettbewerbsvorteil“ realisieren, den es sich ursprünglich von der Fusion oder Übernahme erhofft hatte.
Den nächsten Schritt zur erfolgreichen Integration nach Ihrer nächsten Fusion oder Übernahme gehen
Cloudera kann die Integration von Datenressourcen und Analysefähigkeiten nach einer Fusion zwischen den beiden fusionierenden Unternehmen beschleunigen. Unsere Plattform bietet Skalierbarkeit über den gesamten Datenlebenszyklus hinweg, ein infrastrukturunabhängiges Bereitstellungsmodell und Interoperabilität des Data Lakehouse auf Cloudera-Diensten und Apache Iceberg. Diese Kombination bietet einen architektonischen Blueprint für die Standardisierung von KI/ML-Initiativen und Datenoperationen sowie für die Bereitstellung eines Datenaustauschmodells, das sowohl von Cloudera- als auch von Nicht-Cloudera-Diensten genutzt werden kann.
Für die Vereinbarung einer Demo oder Produktvorführung wenden Sie sich an unser Team.