
RAG-Anwendungen erstellen – der Teufel steckt im Detail
Das Erstellen von Retrieval-Augmented Generation (RAG)-Anwendungen kann schnell komplex werden und erfordert einen sorgfältigen Umgang mit Datenaufnahme, -verarbeitung und -abfrage. Früher war es die Aufgabe von Entwicklern, Daten in Chunks zu zerlegen, Einbettungen einzufügen und Vektordatenbanken zu integrieren.
Einer der häufigsten Fallstricke beim Implementieren einer RAG-Lösung besteht jedoch darin, dass die Abhängigkeiten zwischen diesen Komponenten nicht verstanden werden. Entwickler sollten sich folgende Frage stellen: „Können wir unsere Daten so zerlegen wie sie sind, oder sollten wir sie vor dem Chunking verfeinern?“
Cloudera Data Flow und die exklusiven RAG-Pipeline-Prozessoren von Cloudera vereinfachen den komplexen Prozess der Verfeinerung unstrukturierter Daten durch Partitionierung. Dies ermöglicht ein effektiveres Chunking und qualitativ hochwertigere Vektoreinbettungen. Schlecht konzipierte Partitionierungen oder Chunkings können Leistung und Qualität von Einbettungen beeinträchtigen. Die Tools von Cloudera beseitigen jedoch einen Großteil dieser komplexen Vorgänge und optimieren so die Entwicklung effizienter und zuverlässiger RAG-Lösungen.
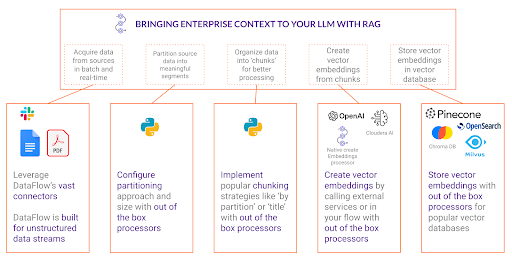
Sehen wir uns die kritischen Phasen eines RAG-Workflows – Partitionieren, Chunking, Einbetten und Einfügen – einmal näher an und zeigen, wie die Technologie von Cloudera die einzelnen Schritte vereinfacht.
Datenpartitionierung: Das Fundament von RAG
Der erste wichtige Schritt eines RAG-Workflows ist die Partitionierung. Bei diesem Prozess werden große, manchmal unstrukturierte Datenquellen in aussagekräftige Segmente zerlegt, um eine programmatische Iteration zu unstrukturierten Daten zu ermöglichen. Natürlich sind Abrufe nach wie vor ohne Partitionierung möglich, aber je detaillierter Ihre Kontrolle über Ihre Verarbeitung ist, desto flexibler sind Sie beim Erstellen von Flows für verschiedene Datenquellen. Die Partitionierung stellt sicher, dass die Daten in überschaubare Portionen strukturiert werden, wobei die Strukturierung auf die Art und Weise ausgerichtet ist, wie Benutzer die Informationen abfragen.
Partitionierungsstrategien variieren je nach Art der Daten. So ermöglicht beispielsweise die Partitionierung nach Abschnittsüberschriften besser organisierte Abrufe, wenn lange Dokumente wie Benutzerhandbücher verarbeitet werden. Im Gegensatz dazu kann eine Partitionierung auch das Zerlegen von Inhalten nach Zeitstempeln umfassen, um bei Konversationsdaten wie Chatprotokollen den Konversationsfluss beizubehalten. Ein weiterer wichtiger Aspekt, der in die Überlegungen einbezogen werden sollte, sind Tokenlimits: Da für die meisten Einbettungsmodelle die Tokengröße, die auf einmal verarbeitet werden kann, vordefiniert ist, muss die Partitionierung an diesen Einschränkungen ausgerichtet werden, um eine optimale Leistung zu sicherzustellen.
Ein gut definierter Ansatz für die Partitionierung trägt dazu bei, dass RAG-Anwendungen präzise, effizient und benutzerfreundlich sind. Entwickler können die Qualität von Antworten optimieren, indem sie sicherstellen, dass nur die relevantesten Daten abgerufen und an das Large Language Model (LLM) übergeben werden. Dabei wird außerdem unnötiger Rechenaufwand minimiert.
Chunking: Kontext beibehalten
Nachdem die Partitionierung abgeschlossen ist, geht es im nächsten Schritt um die Segmentierung. Beim Chunking werden zusammengehörige Partitionen gebündelt, um einen aussagekräftigen Kontext beizubehalten. Während beim Partitionieren Inhalte in grundlegende Bestandteile zerlegt werden, wird beim Chunking sichergestellt, dass die Beziehungen dieser Bestandteile beibehalten werden, um zu verhindern, dass Kontext verloren geht.
Ein Beispiel: Eine Klausel oder eine Vorschrift in einem Rechtsdokument kann sich über mehrere Absätze erstrecken. Werden solche Dokumente zu kleinteilig partitioniert, kann bei inhaltlichen Abfragen von Benutzern die Bedeutung verloren gehen. Das Chunking bietet hier Unterstützung, weil dabei zusammengehörige Textsegmente zu einer logisch vollständigen Einheit gruppiert werden. Dadurch wird sichergestellt, dass das Modell genügend Kontextinformationen erhält, wenn ein Benutzer eine Abfrage stellt, um eine genaue und relevante Antwort zu generieren.
Chunking-Strategien variieren je nach der Art der Datensätze. Einige Ansätze beinhalten einfaches Chunking mit fester Länge, bei dem Segmente basierend auf einer vordefinierten Anzahl von Token gruppiert werden. Zu den fortgeschritteneren Strategien zählt etwa das Chunking des Titels eines Dokuments zusammen mit dem zugehörigen Text.
Effektives Chunking verbessert die Suchgenauigkeit, optimiert die Abruflatenz und stellt sicher, dass von einem LLM generierte Antworten kontextbezogen und präzise sind. Darüber hinaus können Sie eine Chunking-Strategie wählen, die auf maximalen Kontexterhalt ausgerichtet ist. Dadurch fließt in die Entscheidung Ihres Einbettungsmodells das vorab festgelegte Wissen über Ihre Chunk-Größen mit ein.
Einbettung: Text in durchsuchbare Vektoren umwandeln
Wenn gut strukturierte Chunks vorhanden sind, ist der nächste Schritt im RAG-Workflow die Einbettung. Einbettungen sind numerische Darstellungen von Text, die es Maschinen ermöglichen, die semantische Bedeutung verschiedener Textsegmente zu verstehen und zu vergleichen. Ohne Einbettung wären RAG-Anwendungen auf einfache Stichwortsuchen beschränkt, denen das kontextuelle Verständnis eines echten semantischen Abrufs fehlt.
Die Einbettung ist ein mehrstufiger Prozess, der Tokenisierung, Vektortransformation und Speicherung umfasst. Wenn ein Text-Chunk ein Einbettungsmodell durchläuft, wird er zunächst in Token zerlegt. Diese Token werden dann in einen vieldimensionalen Vektor umgewandelt, der die wesentlichen Aspekte des Textes in einem Format erfasst, das für Suchvorgänge nach mathematischer Ähnlichkeit, wie der euklidischen Distanz (L2) und der Kosinus-Ähnlichkeit, geeignet ist.
Die Wahl des richtigen Einbettungsmodells ist entscheidend. Einige Modelle sind für allgemeine Abrufe optimiert, während andere auf fachspezifische Anwendungen wie rechtliche, medizinische oder technische Dokumente ausgelegt sind. Ein weiterer wichtiger Aspekt ist die Dimension von Vektoren, die auf das Schema der Vektordatenbank ausgerichtet werden muss. Stimmen die Größen von Vektoren nicht überein, kann dies dazu führen, dass Suchvorgänge weniger effizient sind oder Kompatibilitätsprobleme auftreten.
Sobald Text-Chunks in vektorielle Darstellungen eingebettet sind, können sie mithilfe von Ähnlichkeitsmetriken durchsucht werden. Dies ermöglicht hocheffiziente Abrufe der relevantesten Inhalte bei Benutzerabfragen und verbessert deutlich die Genauigkeit und Reaktionsfähigkeit von RAG-gestützten Anwendungen.
Cloudera Data Flow bietet einen unglaublich leistungsstarken und dennoch einfach zu bedienenden Prozessor für Einbettungen. Damit können Sie ein Modell in Verbindung mit dem Prozessor nutzen und die Möglichkeiten Ihrer Datenflüsse erweitern und besser ausschöpfen. API-Aufrufe sind dabei nicht erforderlich (es sind keine GPUs nötig). Der Prozessor verfügt über drei einfache Eigenschaften:
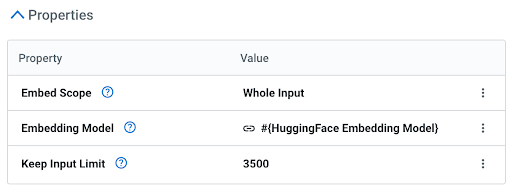
Dadurch können Sie ganz detailliert das beste Einbettungsmodell für jeden Datenfluss auswählen.
Effiziente Abrufe durch eingebettete Chunks in Vektordatenbanken
Der letzte Schritt im RAG-Workflow ist das Einfügen der eingebetteten Chunks in eine Vektordatenbank. Vektordatenbanken sind so konzipiert, dass sie Ähnlichkeitssuchen extrem schnell durchführen. Dies ermöglicht es Benutzern, durch Abfragen relevante Inhalte effizient abzurufen.
Herkömmliche Datenbanken beruhen auf einer strukturierten Indizierung, um exakte Übereinstimmungen hervorzubringen. Vektordatenbanken hingegen nutzen Ähnlichkeitssuchen und Algorithmen wie ANN und KNN, um Einbettungen zu finden, die Suchanfragen von Benutzern sehr nahe kommen. Auf diese Weise können RAG-Anwendungen semantisch relevante Inhalte selbst dann abrufen, wenn der Wortlaut einer Abfrage nicht exakt mit dem gespeicherten Text übereinstimmt.
Nachdem die eingebetteten Daten in die Vektordatenbank eingefügt wurden, ist das System für Echtzeitabfragen bereit. Wenn ein Benutzer eine Abfrage sendet, wird diese in eine Einbettung umgewandelt und mit den gespeicherten Vektoren abgeglichen. Dann werden die relevantesten Ergebnisse abgerufen, die die Grundlage für die Antwort des LLM bilden.
Cloudera Data Flow bietet viele Prozessoren für Verbindungen zu Vektordatenbanken wie Milvus, Pinecone und Chroma. Weitere sind derzeit in Vorbereitung.
Optimieren Sie Ihre RAG-Anwendungsentwicklung noch heute
Mit Cloudera Data Flow und dessen spezialisierten RAG Pipeline-Prozessoren können Unternehmen nun einfacher denn je RAG-Anwendungen erstellen, bereitstellen und optimieren. Die Lösungen von Cloudera sorgen für deutlich weniger technische Komplexität. Entwickler können sich daher ganz darauf konzentrieren, die Abrufgenauigkeit zu erhöhen, generierte Antworten zu optimieren und die allgemeine Benutzererfahrung zu verbessern.
Die RAG-Lösungen können von Unternehmen rasch implementiert werden und sind effizient skalierbar. Darüber hinaus liefern sie präzise, kontextbezogene Antworten auf Basis der exklusiven Integrationsprozessoren von Cloudera für Partitionierung, Chunking, Einbettungen und Vektordatenbanken.
Wenn Sie erfahren möchten, wie Cloudera Sie bei der Optimierung Ihrer RAG-Anwendungsentwicklung unterstützen kann, wenden Sie sich an unser Team, um eine Demo zu erhalten. Weitere Informationen finden Sie zudem in unserer technischen Dokumentation.
Schauen Sie wieder vorbei, damit Sie den geplanten Deep Dive über fortschrittliche RAG-Optimierungstechniken nicht verpassen!
Weitere Informationen:
Um die neuen Funktionen von Cloudera Data Flow 2.9 kennenzulernen und zu erfahren, wie die Lösung Ihre Datenpipelines transformieren kann, sehen Sie sich dieses Video an.
