Erschließung des Potenzials der Unternehmens-KI: Wissensdistillation für die Analyse des Kundensupports





Unternehmen stehen heute vor einer großen Herausforderung: Sie möchten fortschrittliche KI-Modelle nutzen, um wettbewerbsfähig zu bleiben, müssen aber gleichzeitig die hohen Kosten cloudbasierter Large Language Models (LLMs) unter Kontrolle halten und die Datenschutzbestimmungen einhalten.
Wie können Unternehmen also modernste KI nutzen, ohne ihre Budgets zu überziehen oder vertrauliche private Daten preiszugeben? Bei Cloudera haben wir eine Lösung entwickelt, die diese Herausforderung in eine Chance verwandelt: Wir nutzen synthetische Daten, die aus privaten Daten und Wissensdestillation generiert werden, um kosteneffiziente, genaue und konforme KI-Systeme zu erstellen.
In diesem Artikel erklären wir, wie das Synthetic Data Generation Studio von Cloudera, das Teil von Cloudera AI Studios ist, Unternehmen dabei unterstützt, von KI-Innovationen zu profitieren, auch wenn echte Daten fehlen oder vertraulich sind.
Anwendungsfall und wichtige Erkenntnisse
Anwendungsfall: Anhand eines internen Anwendungsfalls zeigen wir, wie wir die Leistung und den Gesamtdurchsatz der Ticket-Pipeline des Kundensupports von Cloudera durch Wissensdestillation unter Verwendung synthetischer Daten, die aus privaten Daten generiert wurden, deutlich verbessert haben, während gleichzeitig der Datenschutz und die Einhaltung gesetzlicher Vorschriften gewährleistet blieben.
Wichtigste Erkenntnisse:
Datenschutz als Wettbewerbsvorteil: Synthetische Daten ermöglichen Innovationen ohne regulatorische Risiken.
Kosteneffiziente Leistung: Kleinere, optimierte Modelle übertreffen größere, ressourcenintensive Alternativen.
Anwendbar auf mehrere Anwendungsfälle: Der gleiche Ansatz kann Anwendungsfälle von der Betrugserkennung bis zum personalisierten Kundenservice unterstützen.
Geschäftliche Herausforderung: Gleichgewicht zwischen Geschwindigkeit und Genauigkeit von KI-Modellen ohne Beeinträchtigung des Datenschutzes
Das Kundensupport-Team von Cloudera nutzt KI-Modelle zur Analyse und Zusammenfassung von Kundensupport-Tickets in Echtzeit. Das System verarbeitet als Eingabe Kommentare von Kunden oder Cloudera-Supportmitarbeitern. Dann analysiert es jeden Kommentar und extrahiert eine Reihe von Analysen, z. B. Sentimentanalysen und Zusammenfassungen. Diese Analysen sind für die Verbesserung des Kundenerlebnisses bei Cloudera von entscheidender Bedeutung.
Aufgrund der sensiblen Natur der in dieser Pipeline verarbeiteten Kundendaten können nur Modelle verwendet werden, die in lokalen Umgebungen ausgeführt werden, und es dürfen keine Kundendaten an externe Quellen übermittelt werden.
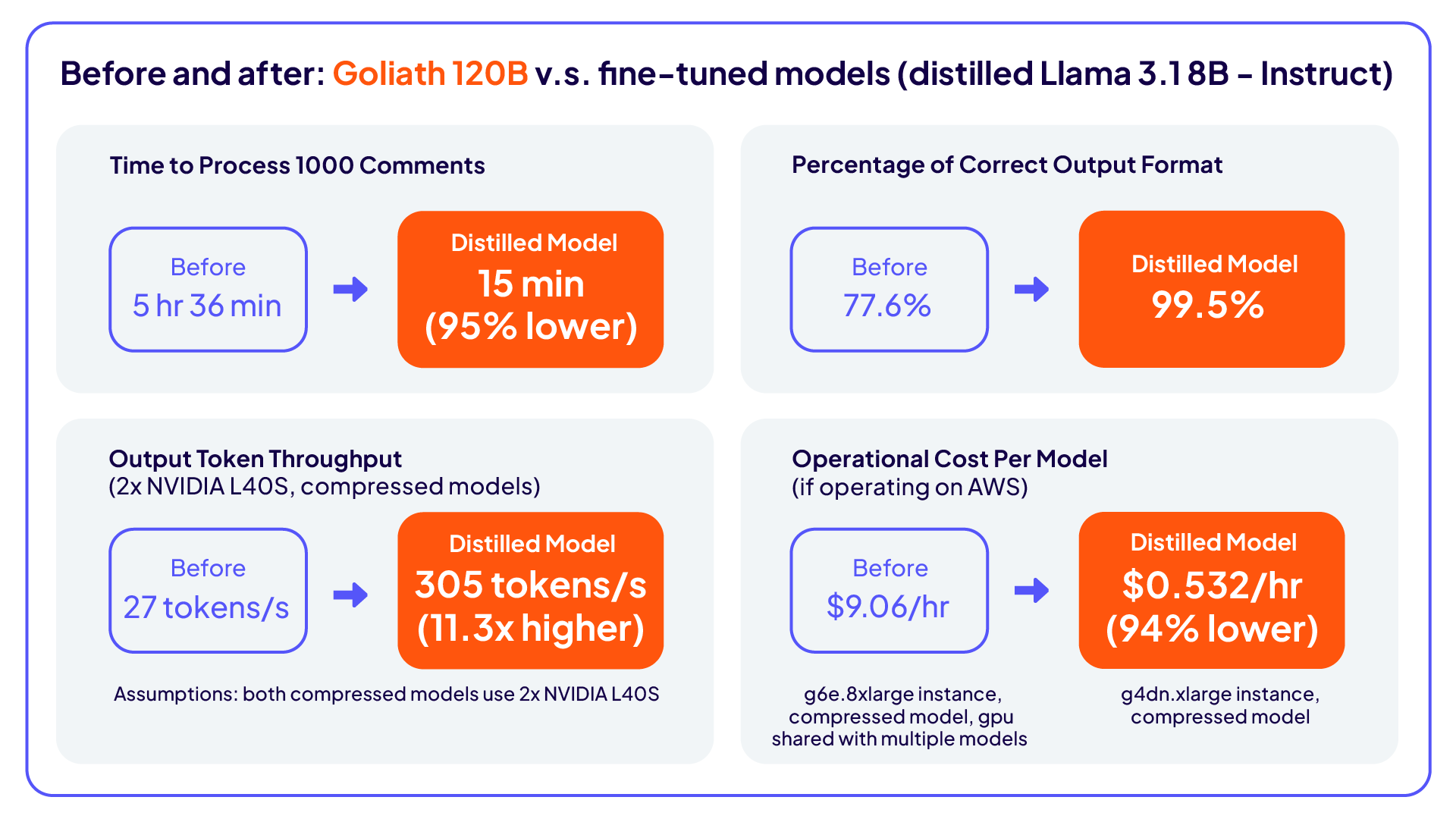
Anfangs stützte sich das Team bei der Analyse der Kommentare auf lokale LLMs (Goliath 120B), die zwar die grundlegenden Leistungsanforderungen erfüllten, jedoch bei Geschwindigkeit und Generierungsleistung zurückfielen: Im Durchschnitt dauerte die Bearbeitung jeder Anfrage 12 bis 15 Sekunden, und alle 30 Sekunden ging eine neue Anfrage ein. Die Übereinstimmung mit dem erwarteten Ergebnis betrug 77,5 %, und die Genauigkeit der Generierung war geringer als bei proprietären Modellen – ein Engpass für die Skalierbarkeit und die Leistung von LLMs.
Die Herausforderungen bei der Verwendung großer lokaler LLMs (Goliath-120B) waren klar: langsamere Reaktionszeiten, höhere Kosten, geringere Generierungsgenauigkeit als bei hochmodernen, Cloud-basierten Modellen und Compliance-Risiken.
Große Unternehmen stehen vor ähnlichen Kompromissen: Sie müssen die Genauigkeit und Geschwindigkeit der KI gegen die Risiken der Datenfreigabe abwägen.
Die Lösung von Cloudera: Wissensdestillation mit privaten Daten
Der Durchbruch von Cloudera liegt in einem datenschutzorientierten Ansatz zur Wissensdestillation.
Anstatt Modelle anhand von Rohkundendaten zu trainieren, die mit regulatorischen Risiken und Offenlegungsrisiken verbunden waren, haben wir mithilfe von Cloudera Synthetic Data Studio synthetische Datensätze generiert. Dieses neue Low-Code-Tool in Cloudera AI ahmte reale Interaktionen nach – technische Fragen, Szenarien zur Fehlerbehebung und mehr – ohne jemals private Daten offenzulegen.
Die Generierung synthetischer Kundensupport-Interaktionen hatte Vorteile in Bezug auf Regulierung und Risiko und ermöglichte dem Team außerdem die Übermittlung der synthetischen Daten an hochmoderne, cloudbasierte LLMs, um Erkenntnisse wie die Kundenstimmung aus den leistungsstärksten LLMs zu gewinnen. Diese cloudbasierten LLMs lieferten wesentlich genauere Informationen als große lokale LLMs und waren somit eine ideale Quelle zur Gewinnung präziser Erkenntnisse aus diesen hochmodernen LLMs.
Die synthetische Datenlösung von Cloudera eliminierte sämtliche Compliance- und Datenschutzrisiken und generierte synthetische Daten von höchster Qualität (sogar höher als bei vorhandenen großen, lokalen LLMs). Dieser Ansatz eröffnete die Möglichkeit der Übertragung von Wissen aus hochmodernen Modellen auf kleine LLMs und löste dasselbe Problem wie Goliath-120B, jedoch zu geringeren Kosten und mit höherer Genauigkeit.
Unser Prozess
Datengenerierung: Mithilfe des Datengenerierungs-Workflows von Synthetic Data Studio haben wir einen Prompt erstellt, der Claude Sonnet anweist, Kundenfragen und -antworten zu generieren. Der Prompt weist den LLM an, Fragen und Antworten für den Kundensupport zu erstellen, den Ton vorzugeben und die Struktur detailliert darzulegen. Darüber hinaus stellen wir eine Liste mit Themen bereit, die in echten Daten vorkommen (z. B. Kundensupport für Cloudera AI oder Cloudera Data Warehouse), und verwenden Startthemen, um eine vielfältige und praxisnahe Generierung von Kundensupport-Tickets sicherzustellen.
Optimierung: Unter Verwendung ausschließlich der gefilterten Daten teilte das Team die Daten in Trainings- und Entwicklungsdaten auf und übertrug das Wissen aus dem Claude Sonnet-Modell auf ein Meta Llama3.1-8B-instruct- Modell. Das Team führte mehrere Experimente durch, um die Optimierungsparameter zur Maximierung der Leistung des destillierten LLM auszuwählen.
Bewertung: Mithilfe des Bewertungs-Workflows von Synthetic Data Studio erstellte das Team einen Prompt, um einem LLM-as-a-Judge Anweisungen zur Bewertung der Qualität der generierten Daten zu geben, und filterte Proben von geringer Qualität heraus.
Mithilfe von sowohl manuellen als auch automatisierten LLM-as-a-Judge-Bewertungen bewertete das Team echte Fragen und Antworten aus dem Kundensupport. Das Team von Cloudera konzentrierte sich auf Antworten, bei denen sich die eingesetzten und destillierten LLMs unterschieden, und berichtete über die Gewinnrate jedes LLM. Darüber hinaus ermittelte es Geschwindigkeitsverbesserungen in Bezug auf die durchschnittliche Laufzeit, die Einhaltung der erwarteten Leistung und die Kosten für die Bereitstellung des Modells.
Die Ergebnisse
Verbesserte Geschwindigkeit: Die Verarbeitungszeit wurde um 95 % reduziert.
Bessere Ausgabestruktur: Die Ausgabegenauigkeit stieg von 77,5 % auf 99,5 %.
Höhere LLM-Genauigkeit: Beim Vergleich des kleineren destillierten LLM (Llama 3.1 8B) mit dem eingesetzten Goliath LLM (Goliath 120B) betrug die Gewinnrate 70 % gegenüber 30 % bei Verwendung von Phi-4 als Richter und 63 % gegenüber 37 % bei Verwendung menschlicher Gutachter zum Vergleich der beiden Modelle.
Verbesserte Kosten und Effizienz: Das kleinere destillierte LLM reduzierte den Rechen- und Speicherbedarf, erhöhte gleichzeitig die Skalierbarkeit in Echtzeit und gewährleistete den Datenschutz, während sich der Durchsatz um das 11-fache verbesserte.
Die Ergebnisse sind eindeutig: Unternehmen können Spitzenleistungen im Bereich KI erzielen, ohne dabei den Datenschutz zu beeinträchtigen. Durch die Synthese von Trainingsdaten und das Destillieren von Wissen vermeiden Unternehmen Kompromisse zwischen Innovation und Compliance.
Synthetische Daten ermöglichen Innovationen ohne regulatorisches Risiko
Durch die Entwicklung eines Ansatzes zur Wissensdestillation gelang Cloudera eine Reduzierung der Verarbeitungszeit um 95 %, eine Erhöhung der Einhaltung der Ausgabestruktur auf 99,5 % und die Bereitstellung eines destillierten Llama 3.1 8B-Modells, das das vorherige Goliath 120B-Modell bei der Genauigkeit (gemessen anhand von Phi-4) um 70 % und bei der menschlichen Bewertung um 63 % übertraf.
Diese Methode eliminierte Compliance-Risiken durch die Vermeidung der direkten Verwendung sensibler Daten und ermöglichte zudem einen 11-fach höheren Durchsatz. Damit wurde gezeigt, dass kleinere, genau abgestimmte Modelle größere, ressourcenintensive Alternativen sowohl in Bezug auf Geschwindigkeit als auch Präzision übertreffen können.
Testen Sie unser AMP, um zu erfahren, wie Sie private synthetische Daten nutzen können, um Wissen aus einem großen Modell in ein kleineres Modell für einen Kundensupport-Anwendungsfall zu übertragen.