Apache Storm
Ein System zur Verarbeitung von Streaming-Daten in Echtzeit
Apache™ Storm ergänzt Enterprise Hadoop um zuverlässige Echtzeit-Datenverarbeitungsfunktionen. Storm on YARN ist leistungsstark für Szenarien, in denen Echtzeitanalysen, maschinelles Lernen und kontinuierliche Überwachung des Betriebs erforderlich sind.
Storm lässt sich über Apache Slider in YARN integrieren. YARN verwaltet Storm und berücksichtigt gleichzeitig Cluster-Ressourcen für Daten-Governance-, Sicherheits- und Betriebskomponenten einer modernen Datenarchitektur.

Was genau macht Storm
Storm ist ein verteiltes Echtzeit-Rechensystem zur Verarbeitung großer Datenmengen mit hoher Geschwindigkeit. Storm ist extrem schnell und kann über eine Million Datensätze pro Sekunde und Knoten in einem Cluster von geringer Größe verarbeiten. Unternehmen nutzen diese Geschwindigkeit und kombinieren sie mit anderen Datenzugriffsanwendungen in Hadoop, um unerwünschte Ereignisse zu verhindern oder positive Ergebnisse zu optimieren.
Einige der besonderen neuen Geschäftsmöglichkeiten umfassen: Kundendienstmanagement in Echtzeit, Datenmonetarisierung, operative Dashboards oder Cybersicherheitsanalysen und Bedrohungserkennung.
Hier finden Sie einige typische Anwendungsfälle zur Vorbeugung und Optimierung von Storm.
| "Prevent" Use Cases | "Optimize" Use Cases | |
|---|---|---|
| Financial Services |
|
|
| Telecom |
|
|
| Retail |
|
|
| Manufacturing |
|
|
| Transportation |
|
|
| Web |
|
|
Storm ist simpel und Entwickler können Storm-Topologien mit jeder Programmiersprache schreiben. Aufgrund seiner fünf Merkmale eignet sich Storm ideal für Datenverarbeitungsaufgaben in Echtzeit. Storm ist:
- Schnell – Benchmarking für die Verarbeitung von einer Million 100-Byte-Nachrichten pro Sekunde und Knoten
- Skalierbar – mit parallelen Berechnungen, die auf einem Cluster von Rechnern ausgeführt werden
- Fehlertolerant - sofern Worker ausfallen, startet Storm sie automatisch neu. Falls ein Knoten ausfällt, wird der Worker automatisch auf einem anderen Knoten neu gestartet.
- Zuverlässig – Storm garantiert, dass jede Dateneinheit (Tupel) mindestens einmal oder genau einmal verarbeitet wird. Nachrichten werden nur bei Fehlern wiedergegeben.
- Einfach zu bedienen – Standardkonfigurationen sind für die Produktion am ersten Tag geeignet. Einmal eingesetzt, ist Storm einfach zu bedienen.
So funktioniert Storm
Ein Sturmcluster besteht aus drei Knotensätzen:
- Nimbus-Knoten (Masterknoten, ähnlich dem Hadoop JobTracker):
- Lädt Berechnungen zur Ausführung hoch
- Verteilt Code über den Cluster
- Startet Worker im gesamten Cluster
- Überwacht die Berechnung und ordnet Worker nach Bedarf neu zu
- ZooKeeper-Knoten – koordiniert den Storm-Cluster
- Supervisor-Knoten – kommuniziert mit Nimbus über Zookeeper, startet und stoppt Worker gemäß den Signalen von Nimbus

Fünf Schlüsselabstraktionen verdeutlichen, wie Storm Daten verarbeitet:
- Tupel– eine geordnete Liste von Elementen. Zum Beispiel könnte ein „4-Tupel“ (7, 1, 3, 7) sein
- Streams – eine unbegrenzte Folge von Tupeln.
- Spouts –Stream-Quellen in einer Berechnung (z. B. eine Twitter API)
- Bolts – Verarbeitung von Eingangs-Streams und Generierung von Ausgangs-Streams. Sie können: Funktionen ausführen; Daten filtern, aggregieren oder verknüpfen; oder mit Datenbanken kommunizieren.
- Topologien – die Gesamtberechnung, visuell dargestellt als Netzwerk von Spouts und Bolts (wie in der folgenden Abbildung)
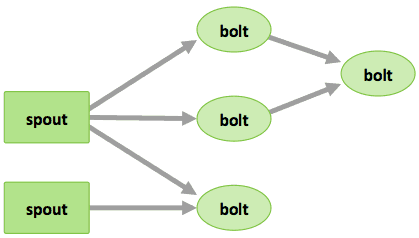
Storm-Benutzer definieren Topologien für die Vorgehensweise der Verarbeitung von Daten, die vom Spout eingehen. Wenn die Daten eingehen, werden sie verarbeitet und die Ergebnisse an Hadoop übergeben.