Übersicht
Data-Lake-Flexibilität und Data-Warehouse-Leistung auf einer einzigen Plattform.
Ein offenes Data Lakehouse hilft Unternehmen dabei, schnelle Analysen für alle strukturierten und unstrukturierten Daten in großem Umfang durchzuführen. Es beseitigt Datensilos und ermöglicht Datenteams die Zusammenarbeit an denselben Daten mit den Tools ihrer Wahl in jeder Public und Private Cloud.
Diese moderne Datenarchitektur ermöglicht Datenzuverlässigkeit und eine einfache Datenverwaltung. Führen Sie BI-, KI-, ML- und Streaming-Analysen für dieselben Daten aus, ohne Ihre Daten je verschieben oder sperren zu müssen.
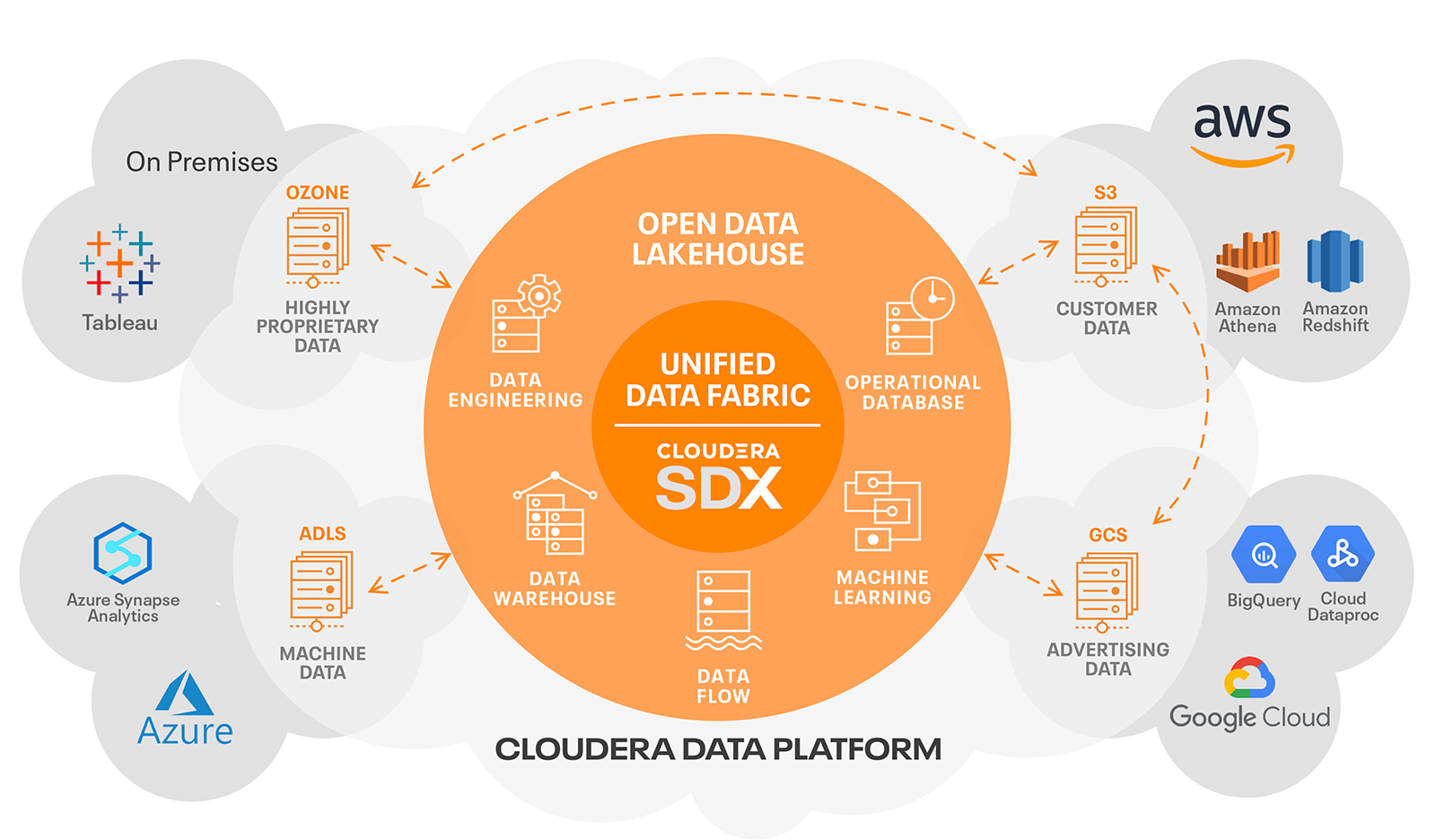
Die Cloudera Data Platform (CDP) bietet das weltweit einzige offene Data Lakehouse, das die folgenden Vorteile bietet:
Offene Architektur
Das Data Lakehouse von Cloudera, das auf Apache Iceberg basiert, ist zu 100 % offen: Es basiert auf Open Source, offenen Standards, die in der Community breite Akzeptanz finden. Es kann verschiedene Datenformate speichern und ermöglicht es, dass mehrere Engines an denselben Daten arbeiten.
Einfache Übernahme
Durch die Integration von Iceberg direkt in Shared Data Experience (SDX) bietet Cloudera die einfachste Möglichkeit zur Bereitstellung eines Lakehouse. Zusätzliche Funktionen wie die Schemaweiterentwicklung, verborgene Partitionierung und eine vereinfachte Datenverwaltung für große Datensätze.
Multi-Cloud
Erstellen Sie ein Lakehouse an einem beliebigen Ort: in jeder Public Cloud oder in Ihrem eigenen Rechenzentrum. Erstellen Sie es einmal und führen Sie es überall aus – ohne sich den Kopf zu zerbrechen. Cloudera bietet dieselben Datenservices mit vollständiger Portabilität in alle Clouds.
Sicher und verwaltet
Die Iceberg-Tabellen in der CDP sind in SDX integriert und ermöglichen einheitliche Sicherheit, fein abgestimmte Richtlinien, Governance sowie Herkunfts- und Metadatenmanagement über mehrere Clouds hinweg, sodass Sie sich auf die Analyse Ihrer Daten konzentrieren können, während wir uns um den Rest kümmern.
Wichtige Komponenten
Optimieren Sie Ihre Daten mit einem offenen Lakehouse
Offenes Tabellenformat, Apache Iceberg
Apache Iceberg ist der wichtigste Baustein eines offenen Data Lakehouse. Es ist ein leistungsstarkes offenes Tabellenformat für große Analysetabellen, das die Zuverlässigkeit von SQL-Tabellen in Big Data einbringt. Zudem ermöglicht es, dass mehrere Datenverarbeitungs-Engines gleichzeitig arbeiten. Es bietet umfangreiche Funktionen wie Time Travel, Snapshot-Isolation, Schemaweiterentwicklung, verborgene Partitionierung und mehr.
Offenes Tabellenformat, Apache Iceberg
Apache Iceberg ist der wichtigste Baustein eines offenen Data Lakehouse. Es ist ein leistungsstarkes offenes Tabellenformat für große Analysetabellen, das die Zuverlässigkeit von SQL-Tabellen in Big Data einbringt. Zudem ermöglicht es, dass mehrere Datenverarbeitungs-Engines gleichzeitig arbeiten. Es bietet umfangreiche Funktionen wie Time Travel, Snapshot-Isolation, Schemaweiterentwicklung, verborgene Partitionierung und mehr.
Shared Data Experience (SDX)
SDX ist ein grundlegender Bestandteil der CDP, der einheitliche Sicherheits- und Governance-Technologien umfasst, die auf Metadaten basieren. SDX bietet ein vollständiges Datenmanagement für Daten und Analysen ortsunabhängig in allen Infrastrukturen und reduziert Risiken sowie Betriebskosten. Die IT-Abteilung kann umfassend gesicherte und verwaltete Data Lakehouses schneller bereitstellen und mehr Benutzern uneingeschränkt Zugriff auf eine größere Menge von Daten gewähren.
Shared Data Experience (SDX)
SDX ist ein grundlegender Bestandteil der CDP, der einheitliche Sicherheits- und Governance-Technologien umfasst, die auf Metadaten basieren. SDX bietet ein vollständiges Datenmanagement für Daten und Analysen ortsunabhängig in allen Infrastrukturen und reduziert Risiken sowie Betriebskosten. Die IT-Abteilung kann umfassend gesicherte und verwaltete Data Lakehouses schneller bereitstellen und mehr Benutzern uneingeschränkt Zugriff auf eine größere Menge von Daten gewähren.
Robuster Data Catalog
Suchen, kuratieren und taggen Sie Daten über alle Infrastrukturen hinweg, und generieren Sie mit Cloudera Data Catalog relevante Informationen, um:
Alle Ihre Daten von einem einzigen Ort aus zu durchsuchen, anzuzeigen und darauf zuzugreifen
Daten und deren Verwendung zu verstehen, zu dokumentieren und zu überwachen.
zusammenzuarbeiten und Daten gemeinsam und verantwortungsbewusst mit vollständigem Einblick zu nutzen.
Robuster Data Catalog
Suchen, kuratieren und taggen Sie Daten über alle Infrastrukturen hinweg, und generieren Sie mit Cloudera Data Catalog relevante Informationen, um:
Alle Ihre Daten von einem einzigen Ort aus zu durchsuchen, anzuzeigen und darauf zuzugreifen
Daten und deren Verwendung zu verstehen, zu dokumentieren und zu überwachen.
zusammenzuarbeiten und Daten gemeinsam und verantwortungsbewusst mit vollständigem Einblick zu nutzen.