Fast Forward Labs Research jetzt ohne Abonnement verfügbar
In Zukunft werden alle neuen Reports öffentlich verfügbar sein und können kostenlos heruntergeladen werden. Zudem werden wir im Laufe der Zeit Zugriff auf aktualisierte Versionen älterer Reports gewähren. Schauen Sie daher regelmäßig vorbei, um die verfügbaren kostenlosen Forschungsergebnisse zu prüfen.
Kostenlose Forschungs-Reports
Entdecken Sie unsere neuesten Forschungs-Reports und Prototypen, die für alle frei zugänglich sind.
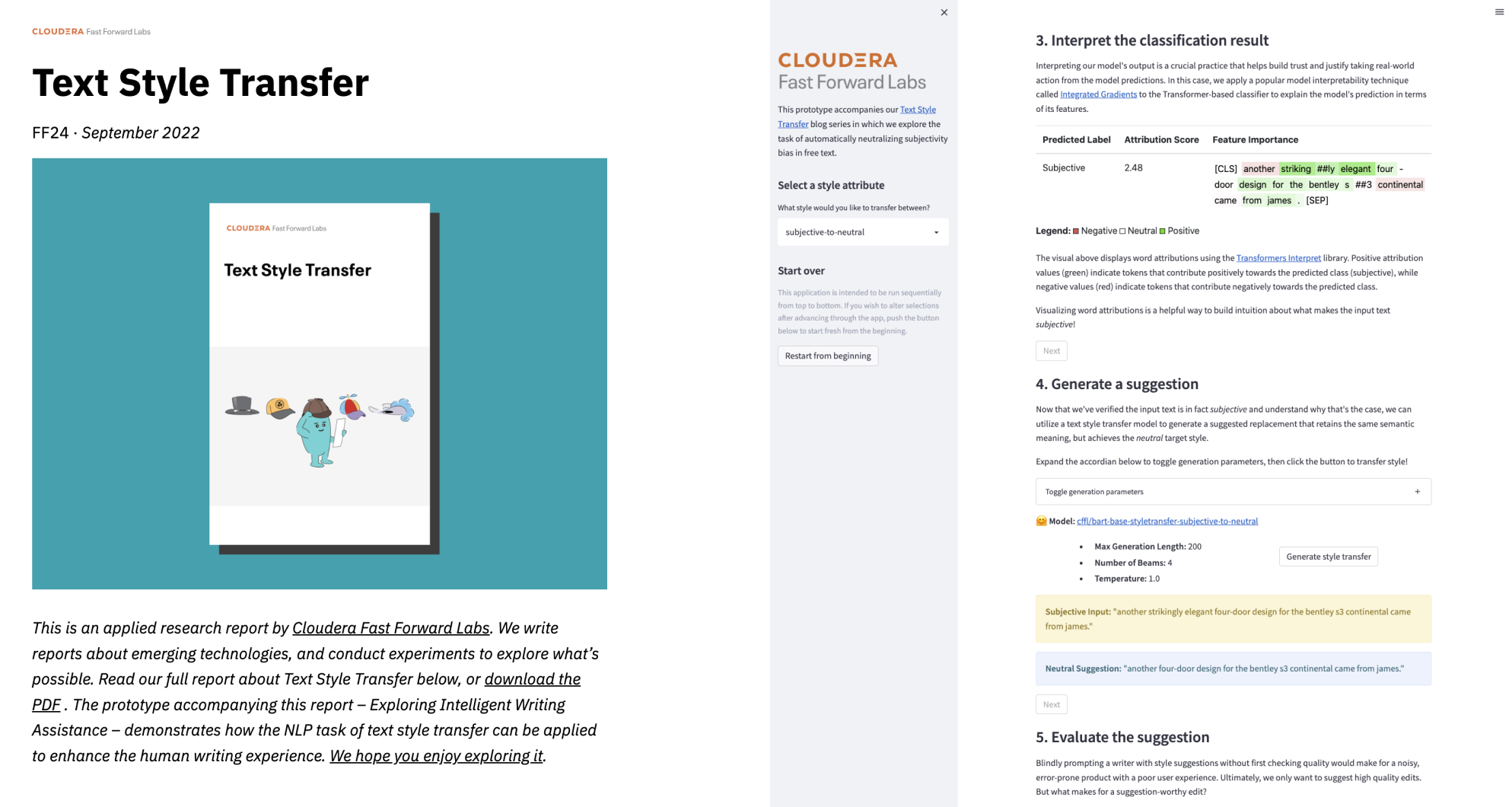
Übertragung des Textstils
Die Aufgabe des NLP der Textstilübertragung (Text Style Transfer – TST) zielt darauf ab, die Stilmerkmale eines Textes automatisch zu kontrollieren, ohne den Inhalt zu verändern. Dies ist ein wichtiger Gesichtspunkt, um NLP nutzerorientierter zu gestalten. In diesem Report untersuchen wir die Textstilübertragung anhand eines Anwendungsfalls – der Neutralisierung von Verzerrungen durch Subjektivität im Freitext. Dabei beschreiben wir unseren sequenzbasierten Modellierungsansatz, der HuggingFace Transformers verwendet, und stellen eine Reihe von benutzerdefinierten, referenzlosen Bewertungsmetriken zur Quantifizierung der Modellleistung vor. Wir schließen mit einer ethischen Diskussion ab, die sich um unseren Prototypen dreht: Untersuchung intelligenter Schreibassistenz.
Ableiten eines Concept Drift ohne vorklassifizierte Daten
Ein Concept Drift tritt auf, wenn sich die statistischen Eigenschaften einer Zieldomäne im Laufe der Zeit verändern, was zu einer Verschlechterung der Leistungsfähigkeit eines Modells führt. Drifts werden in der Regel im Rahmen der Überwachung einer Leistungskennzahl von Interesse und dem Auslösen einer Neutraining-Pipeline festgestellt, wenn diese Kennzahl unter einen bestimmten Schwellenwert fällt. Dieser Ansatz setzt jedoch voraus, dass zum Zeitpunkt der Vorhersage ausreichend vorklassifizierte Daten zur Verfügung stehen, was für viele Produktionssysteme eine unrealistische Randbedingung darstellt. In diesem Bericht werden verschiedene Ansätze für den Umgang mit Concept Drift untersucht, für Fälle, in denen vorklassifizierte Daten nicht ohne Weiteres verfügbar sind.

Mehrzieloptimierung für Hyperparameter erkunden
Wir entwickeln anhand der „üblichen verdächtigen“ Metriken wie Prognosegenauigkeit, Rückruf und Präzision Modelle für maschinelles Lernen. Diese Metriken sind jedoch selten das Einzige, was uns wirklich interessiert. Produktionsmodelle müssen auch physischen Anforderungen wie Latenzen, Speicherplatzbedarf oder Vorgaben in Bezug auf Fairness entsprechen. Die Optimierung von Hyperparametern gestaltet sich noch schwieriger, wenn mehrere Metriken optimiert werden müssen. Unsere neueste Forschung untersucht dieses Szenario der „Mehrzieloptimierung“ von Hyperparametern im Detail.

Deep Learning für die automatische Offline-Signaturüberprüfung
Bei der Überprüfung handschriftlicher Signaturen geht es um die automatische Unterscheidung zwischen echten und gefälschten Unterschriften. Dies stellt aufgrund der Allgegenwart handschriftlicher Unterschriften als eine Form der Identifizierung in den Bereichen Recht, Finanzen und Verwaltung eine besonders wichtige Herausforderung dar. In diesem Forschungszyklus wurde der Einsatz von Deep-Metric-Learning-Ansätzen – insbesondere Siamesische Netze – in Kombination mit neuartigen Methoden zur Merkmalsextraktion untersucht, um herkömmliche Verfahren zu verbessern.

Session-basierte Empfehlungssysteme
Empfehlungssysteme sind zu einem Grundpfeiler modernen Lebens geworden und umfassen Sektoren wie Onlinehandel, Musik- und Video-Streaming und sogar Content-Publishing. Diese Systeme helfen uns dabei, die große Menge von Inhalten im Internet zu durchsuchen, damit wir herausfinden können, was für uns interessant oder wichtig ist. Ein wichtiger Trend in den letzten Jahren waren session-basierte Empfehlungsalgorithmen, die Empfehlungen rein auf der Grundlage der Interaktionen eines Nutzers in einer laufenden Session geben, ohne dafür Nutzerprofile oder deren gesamte historische Präferenzen zu benötigen.

Textklassifizierung mit wenigen Daten
Die Textklassifizierung kann beispielsweise für Stimmungsanalysen, Themenzuordnungen, zur Dokumentenermittlung oder für Artikelempfehlungen verwendet werden. Es gibt inzwischen Dutzende von Techniken für diese grundlegende Aufgabe. Viele dieser Techniken sind jedoch auf große Mengen an klassifizierten Daten angewiesen, um brauchbare Ergebnisse zu erzielen. Das Erfassen von Annotationen für Ihren Anwendungsfall ist in der Regel einer der kostspieligsten Aspekte jeder Anwendung für maschinelles Lernen. In diesem Bericht untersuchen wir, wie latente Texteinbettungen mit wenigen oder auch gar keinen Trainingsbeispielen verwendet werden können und wir geben Einblicke in bewährte Verfahren zur Implementierung dieser Methode.

Strukturelle Zeitreihen
Zeitreihendaten sind allgegenwärtig. In diesem Bericht werden verallgemeinerte additive Modelle untersucht, die uns mit der Zerlegung der Zeitreihen in strukturelle Komponenten ein einfaches, flexibles und interpretierbares Mittel zur Modellierung von Zeitreihen an die Hand geben. Wir betrachten die Vor- und Nachteile der Anwendung eines Ansatzes zur Kurvenanpassung für Zeitreihen und demonstrieren deren Verwendung anhand der Prophet-Bibliothek von Facebook mit einem Nachfrageprognose-Problem.
Meta-Lernprozesse
Im Gegensatz zu der Art und Weise, wie Menschen lernen, sind Deep-Learning-Algorithmen auf enorme Mengen von Daten und Berechnungen angewiesen und können dennoch an der Generalisierung scheitern. Menschen können sich schnell anpassen, da sie ihr Wissen aus früheren Erfahrungen nutzen, wenn sie mit neuen Problemen konfrontiert werden. In diesem Bericht erläutern wir, wie Meta-Lernprozesse früheres Wissen aus Daten nutzen können, um während der Testzeit neue Aufgaben schnell und effizienter zu lösen.
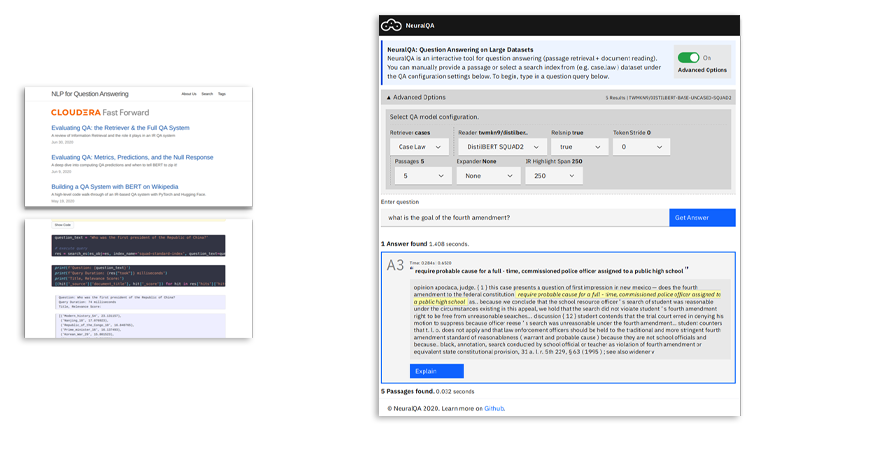
Automatisierte Beantwortung von Fragen
Die automatisierte Beantwortung von Fragen ist eine benutzerfreundliche Methode, um mithilfe natürlicher Sprache Informationen aus Daten zu extrahieren. Dank der jüngsten Fortschritte in der Verarbeitung natürlicher Sprache sind die Möglichkeiten zur Beantwortung von Fragen aus unstrukturierten Textdaten rasch gewachsen. Diese Blog-Serie bietet einen Überblick über die technischen und praktischen Aspekte des Aufbaus eines durchgängigen Frage-Antwort-Systems.
Kausalzusammenhang für maschinelles Lernen
Die Schnittmenge von kausaler Inferenz und maschinellem Lernen ist ein rasch wachsender Forschungsbereich. Er hat bereits Ressourcen hervorgebracht, die robustere, zuverlässigere und fairere Systeme für maschinelles Lernen ermöglichen. Dieser Bericht enthält eine Einführung in die kausale Argumentation, einschließlich Kausalgraphen und invarianter Prognose. Er zeigt außerdem, wie Werkzeuge für kausale Inferenzen zusammen mit klassischen Techniken des maschinellen Lernens in verschiedenen Anwendungsfällen angewendet werden können.

Interpretierbarkeit: Ausgabe 2020
Die Interpretierbarkeit oder die Fähigkeit zu erklären, warum und wie ein System eine Entscheidung trifft, kann uns helfen, Modelle zu verbessern, Vorschriften zu erfüllen und bessere Produkte zu entwickeln. Black-Box-Techniken wie Deep Learning haben neue Maßstäbe auf Kosten der Interpretierbarkeit gesetzt. In diesem kürzlich aktualisierten Report, der nun Techniken wie SHAP enthält, zeigen wir, wie Modelle ohne Einbußen ihrer Fähigkeiten oder Genauigkeit interpretierbar gemacht werden können.
Deep Learning zur Erkennung von Anomalien
Von der Betrugserkennung bis zur Kennzeichnung von Anomalien in Bilddaten gibt es unzählige Anwendungen zur automatischen Identifizierung fehlerhafter Daten. Dieser Prozess kann schwierig sein, insbesondere wenn Sie mit großen, komplexen Daten arbeiten. In diesem Report werden Deep-Learning-Ansätze (Sequenzmodelle, VAEs, GANs) zur Erkennung von Anomalien, deren Verwendung, Leistungsbenchmarks und Produktmöglichkeiten untersucht.
Transfer Learning für die Verarbeitung natürlicher Sprache
Technologien für die Verarbeitung natürlicher Sprache (Natural Language Processing – NLP), die Deep Learning nutzen, können Sprache übersetzen, Fragen beantworten und Texte erzeugen, die von Menschen verfassten Texten ähneln. Die zugrunde liegenden Deep-Learning-Techniken erfordern allerdings kostspielige vorklassifizierte Datensätze, eine teure Infrastruktur und rares Fachwissen. Transfer Learning beseitigt diese Einschränkungen, indem es das Sprachverständnis eines Modells wiederverwendet und anpasst. Transfer Learning eignet sich gut für alle NLP-Anwendungen. In diesem Report zeigen wir, wie Sie mithilfe von Transfer Learning leistungsstarke NLP-Systeme mit minimalen Ressourcen aufbauen können.

Lernen mit begrenzt vorklassifizierten Daten
Durch die Möglichkeit, mit einer begrenzten Anzahl vorklassifizierter Daten zu lernen, werden die strengen Anforderungen an vorklassifizierte Daten für überwachtes maschinelles Lernen gelockert. In diesem Bericht geht es um aktives Lernen. Das ist eine Technik, die sich auf die Zusammenarbeit von Maschinen und Menschen stützt, um Daten intelligent vorzuklassifizieren. Aktives Lernen reduziert die Anzahl der zum Trainieren eines Modells erforderlichen vorklassifizierten Beispiele und spart so Zeit und Geld. Dabei wird eine vergleichbare Leistung wie bei Modellen erzielt, die mit wesentlich mehr Daten trainiert wurden. Mit aktivem Lernen können Unternehmen ihren großen Bestand an nicht klassifizierten Daten nutzen, um neue Produktmöglichkeiten zu erschließen.
Föderales Lernen
Federated Learning ermöglicht den Aufbau maschineller Lernsysteme ohne direkten Zugriff auf Trainingsdaten. Die Daten verbleiben an ihrem ursprünglichen Speicherort, wodurch der Datenschutz leichter zu gewährleisten ist und Kommunikationskosten gesenkt werden können. Federated Learning eignet sich hervorragend für den Einsatz in Smartphones und Edge-Hardware, im Gesundheitswesen und anderen, in Bezug auf Datenschutz sensiblen Anwendungsfällen, sowie in industriellen Anwendungen wie der vorausschauenden Wartung.
Semantische Empfehlungen
Das Internet bietet uns eine enorme Auswahl an Lesestoff, Filmen und Einkaufsmöglichkeiten. Aus diesem Grund sind Empfehlungsalgorithmen, die Artikel aufspüren, die eine bestimmte Person interessieren könnten, wichtiger denn je. In diesem Report untersuchen wir Empfehlungssysteme, die den semantischen Inhalt von Artikeln und Anwendern nutzen, um branchenübergreifend umfassendere Empfehlungen abzugeben.

Zusammenfassung
In diesem Bericht werden Methoden für die extraktive Zusammenfassung untersucht, mit der Dokumente automatisch zusammengefasst werden können. Diese Technik lässt sich vielseitig einsetzen: von der Möglichkeit, Tausende von Produktbewertungen auf den Punkt zu bringen, die wichtigsten Inhalte aus langen Nachrichtenartikeln zu extrahieren oder Kundenbiografien automatisch zu Personas zusammenzustellen.
Deep Learning für Bildanalysen – Ausgabe 2019
Convolutional Neural Networks (CNNs oder ConvNets) zeichnen sich durch das Erlernen aussagekräftiger Darstellungen von Funktionen und Konzepten innerhalb von Bildern aus, wodurch CNNs wesentlich zur Lösung von Problemen in mehreren Bereichen beitragen, von der medizinischen Bildgebung bis zur Fertigung. In diesem Bericht zeigen wir, wie Sie die richtigen Deep-Learning-Modelle für Bildanalyseaufgaben und -techniken zum Debuggen von Deep-Learning-Modellen auswählen.
Deep Learning: Bildanalyse
Dieser Bericht untersucht die Historie und den aktuellen Status des tiefen Lernens, erläutert, wie es angewendet wird und prognostiziert künftige Entwicklungen.

Probabilistische Methoden für Echtzeit-Streams
Seit den Zeiten von Analogcomputern, die auf mechanischer Technik basierten, haben wir Systeme rund um den Datenfluss und die kritischen Berechnungen entwickelt, die wir durchführen müssen. Die Philosophie unserer Designs ist zwar konsistent geblieben ist, unsere technischen Grenzen verschieben sich jedoch ständig. In den letzten fünf Jahren konnten wir die Entstehung von „Big Data“ beobachten, die Möglichkeit, Commodity-Infrastrukturen zur Analyse sehr großer Datensätze in einem Batch zu nutzen. Wir sind gerade im Begriff, bei Tools, Methoden und Technologien, die für die Arbeit mit Datenströmen in Echtzeit zur Verfügung stehen, einen bedeutenden Schritt nach vorn zu machen.

Reports nur mit Abonnement
Aktualisierte Versionen älterer Reports werden in Zukunft kostenlos verfügbar sein. Schauen Sie daher regelmäßig vorbei.

Multi-Task Learning
In diesem Bericht konzentrieren wir uns auf Multi-Task Learning, ein neuer Ansatz für maschinelles Lernen, der Algorithmen ermöglicht, Aufgaben parallel zu bewältigen.
{kind=link}

Probabilistische Programmierung
Hier zeigen wir, wie Sie eine probabilistische Programmierung und Bayessche Inferenz verwenden, um Tools mühelos zu entwickeln, die bessere Prognosen für eine effektivere Entscheidungsfindung schaffen.
{kind=link}

Textgenerierung (natürlichsprachliche Generierung)
In diesem Bericht werden wir uns ansehen, wie Maschinensysteme hochstrukturierte Daten in menschliche Sprache umwandeln können.
Lesen Sie den Fast Forward Labs Blog
Halten Sie sich auf dem Laufenden
Melden Sie sich für unseren monatlichen Newsletter an und Sie erhalten die neuesten Informationen über Fortschritte in der angewandten künstlichen Intelligenz sowie Unternehmens-News und Veranstaltungen.